





PrivateGPT: IA para documentos

Los grandes modelos lingüísticos han evolucionado mucho en los últimos años y se han convertido en herramientas eficaces para muchas tareas. El único problema de su uso es que la mayoría de los productos basados en estos modelos utilizan servicios ya preparados de terceras empresas. Este uso tiene el potencial de filtrar datos sensibles, por lo que muchas empresas evitan cargar documentos internos en servicios LLM públicos.
Un proyecto como PrivateGPT podría ser una solución. En principio, está diseñado para un uso totalmente local. Su punto fuerte es que puedes enviar varios documentos como entrada, y la red neuronal los leerá por ti y proporcionará sus propios comentarios en respuesta a tus peticiones. Por ejemplo, puedes "alimentarla" con textos extensos y pedirle que saque algunas conclusiones basadas en la petición del usuario. Esto le permite ahorrar mucho tiempo en la corrección de textos.
Esto es especialmente cierto en campos profesionales como la medicina. Por ejemplo, un médico puede hacer un diagnóstico y pedir a la red neuronal que lo confirme basándose en el conjunto de documentos cargados. Esto permite obtener una opinión independiente adicional, reduciendo así el número de errores médicos. Como las solicitudes y los documentos no salen del servidor, se puede estar seguro de que los datos recibidos no aparecerán en el dominio público.
Hoy le mostraremos cómo desplegar una red neuronal en servidores LeaderGPU dedicados con el sistema operativo Ubuntu 22.04 LTS en tan sólo 20 minutos.
Preparación del sistema
Empieza por actualizar tus paquetes a la última versión:
sudo apt update && sudo apt -y upgradeAhora, instala paquetes adicionales, bibliotecas y el controlador gráfico de NVIDIA®. Todos ellos serán necesarios para compilar correctamente el software y ejecutarlo en la GPU:
sudo apt -y install build-essential git gcc cmake make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev zlib1g-dev libncursesw5-dev libgdbm-dev libc6-dev zlib1g-dev libsqlite3-dev tk-dev libssl-dev openssl libffi-dev lzma liblzma-dev libbz2-devInstalación de CUDA® 12.4
Además del controlador, es necesario instalar el kit de herramientas NVIDIA® CUDA®. Estas instrucciones se han probado en CUDA® 12.4, pero todo debería funcionar también en CUDA® 12.2. Sin embargo, ten en cuenta que tendrás que indicar la versión que tienes instalada cuando especifiques la ruta a los archivos ejecutables.
Ejecute el siguiente comando secuencialmente:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinsudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2204-12-4-local_12.4.0-550.54.14-1_amd64.debsudo cp /var/cuda-repo-ubuntu2204-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/sudo apt-get update && sudo apt-get -y install cuda-toolkit-12-4Puede encontrar más información sobre la instalación de CUDA® en nuestra Base de conocimientos. Ahora, reinicie el servidor:
sudo shutdown -r nowPyEnv install
Es hora de instalar una sencilla utilidad de control de versiones de Python llamada PyEnv. Este es un fork significativamente mejorado del proyecto similar para Ruby (rbenv), configurado para trabajar con Python. Se puede instalar con un script de una línea:
curl https://pyenv.run | bashAhora, necesitas añadir algunas variables al final del archivo script, que se ejecuta al iniciar sesión. Las tres primeras líneas son responsables del correcto funcionamiento de PyEnv, y la cuarta es necesaria para Poetry, que se instalará más tarde:
nano .bashrcexport PYENV_ROOT="$HOME/.pyenv"
[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init -)"
export PATH="/home/usergpu/.local/bin:$PATH"Aplica la configuración que has hecho:
source .bashrcInstala la versión 3.11 de Python:
pyenv install 3.11Crear un entorno virtual para Python 3.11:
pyenv local 3.11Instalación de poesía
La siguiente pieza del puzzle es Poetry. Se trata de un análogo de pip para la gestión de dependencias en proyectos Python. El autor de Poetry estaba cansado de lidiar constantemente con diferentes métodos de configuración, como setup.cfg, requirements.txt, MANIFEST.ini, y otros. Esto se convirtió en el motor para el desarrollo de una nueva herramienta que utiliza un archivo pyproject.toml, que almacena toda la información básica acerca de un proyecto, no sólo una lista de dependencias.
Instalar Poesía:
curl -sSL https://install.python-poetry.org | python3 -PrivateGPT install
Ahora que todo está listo, puede clonar el repositorio PrivateGPT:
git clone https://github.com/imartinez/privateGPTVe al repositorio descargado:
cd privateGPTEjecute la instalación de dependencias utilizando Poetry mientras habilita los componentes adicionales:
- ui - añade una interfaz web de gestión basada en Gradio a la aplicación backend;
- embedding-huggingface - habilita el soporte para incrustar modelos descargados de HuggingFace;
- llms-llama-cpp - añade soporte para la inferencia directa de modelos en formato GGUF;
- vector-stores-qdrant - añade la base de datos vectorial qdrant.
poetry install --extras "ui embeddings-huggingface llms-llama-cpp vector-stores-qdrant"Establezca su token de acceso a Hugging Face. Para más información, lea este artículo:
export HF_TOKEN="YOUR_HUGGING_FACE_ACCESS_TOKEN"Ahora, ejecuta el script de instalación, que descargará automáticamente el modelo y los pesos (Meta Llama 3.1 8B Instruct por defecto):
poetry run python scripts/setupEl siguiente comando recompilar llms-llama-cpp por separado para habilitar el soporte de NVIDIA® CUDA®, con el fin de descargar las cargas de trabajo a la GPU:
CUDACXX=/usr/local/cuda-12/bin/nvcc CMAKE_ARGS="-DGGML_CUDA=on -DCMAKE_CUDA_ARCHITECTURES=native" FORCE_CMAKE=1 pip install llama-cpp-python --no-cache-dir --force-reinstall --upgradeSi aparece un error como nvcc fatal : Unsupported gpu architecture 'compute_', especifique la arquitectura exacta de la GPU que está utilizando. Por ejemplo DCMAKE_CUDA_ARCHITECTURES=86 para NVIDIA® RTX™ 3090.
El último paso antes de empezar es instalar el soporte para llamadas asíncronas (async/await):
pip install asyncioPrivateGPT run
Ejecuta PrivateGPT utilizando un único comando:
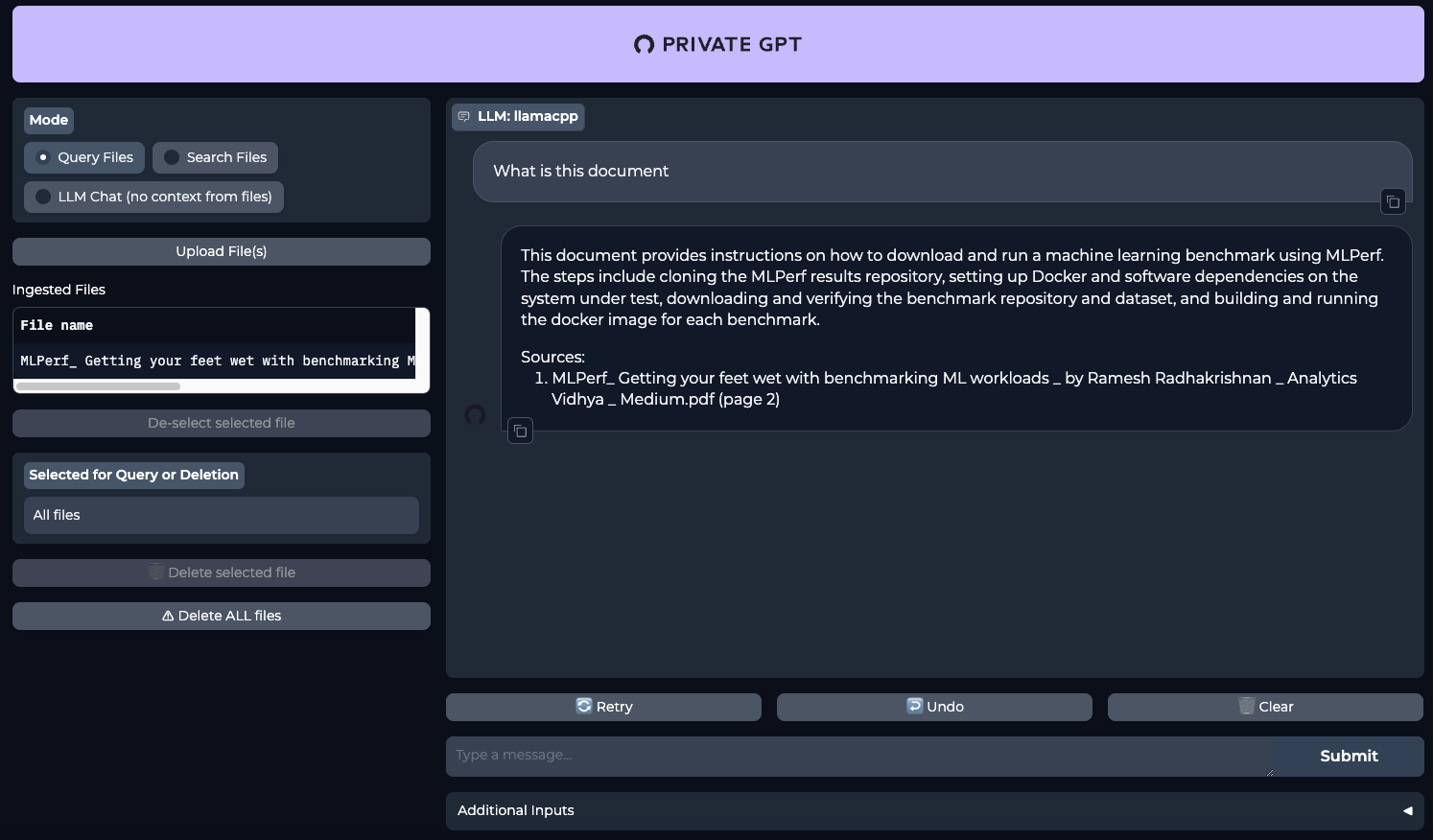
make runAbra su navegador web y vaya a la página http://[LeaderGPU_server_IP_address]:8001
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




