





Stable Diffusion: LoRA selfie

Puedes crear tu primer conjunto de datos con una cámara sencilla y un fondo bastante uniforme, como una pared blanca o una cortina monótona. Para un conjunto de datos de muestra, he utilizado una cámara sin espejo Olympus OM-D EM5 Mark II con objetivos de kit 14-42. Esta cámara admite el control remoto desde cualquier smartphone y un modo de disparo continuo muy rápido.
Monté la cámara en un trípode y establecí la prioridad de enfoque en cara. A continuación, seleccioné el modo en el que la cámara captura 10 fotogramas consecutivos cada 3 segundos e inicié el proceso. Durante el proceso de disparo, giré lentamente la cabeza en la dirección seleccionada y cambié de dirección cada 10 fotogramas:

El resultado fueron unos 100 fotogramas con un fondo monótono:
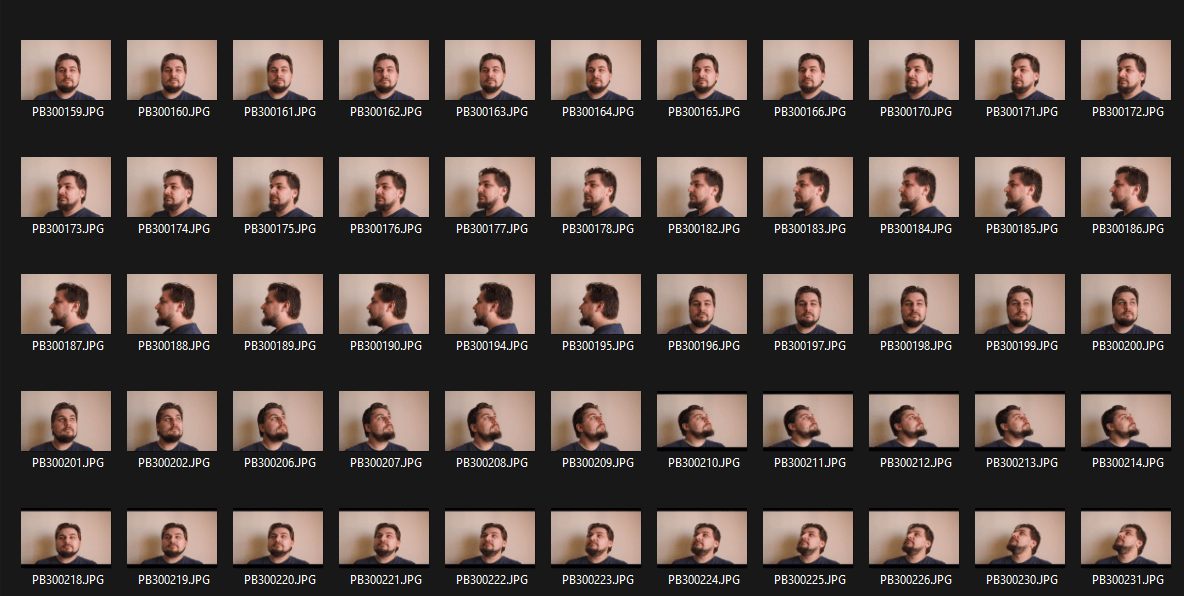
El siguiente paso es eliminar el fondo y dejar el retrato sobre un fondo blanco.
Eliminar el fondo
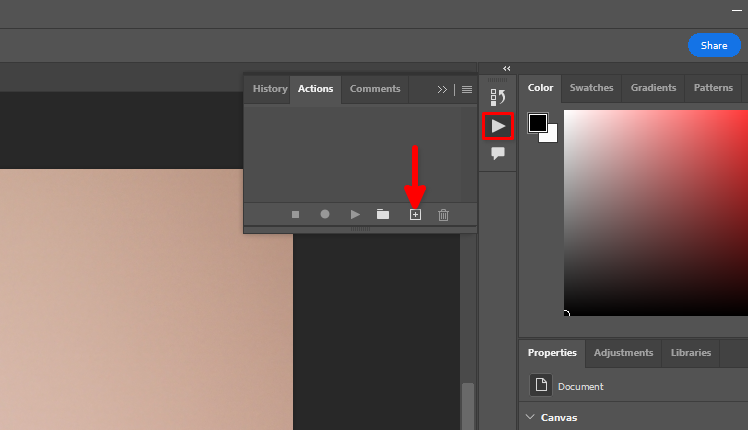
Puede utilizar la función estándar de Adobe Photoshop Remove background y el procesamiento por lotes. Vamos a almacenar las acciones que queremos aplicar a cada imagen de un conjunto de datos. Abra cualquier imagen, haga clic en el icono del triángulo y, a continuación, haga clic en el símbolo +:
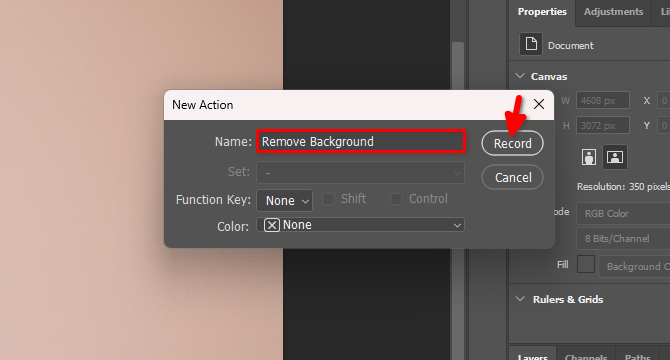
Escriba el nombre de la nueva acción, por ejemplo, Remove Background y haga clic en Record:
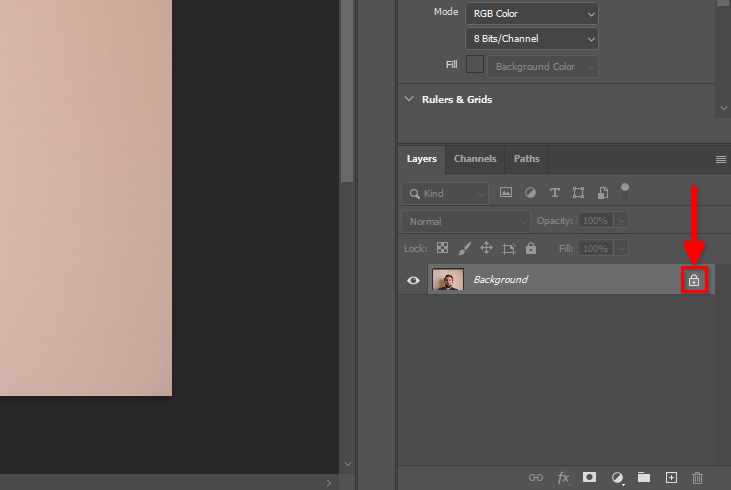
En la pestaña Layers, busque el símbolo del candado y haga clic en él:
A continuación, haga clic en el botón Remove background del panel flotante:
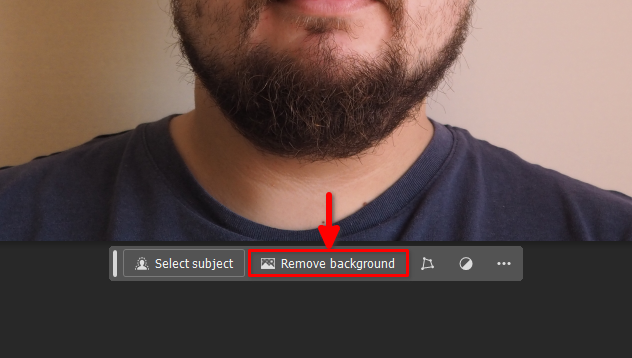
Haga clic con el botón derecho del ratón en Layer 0 y seleccione Flatten Image:
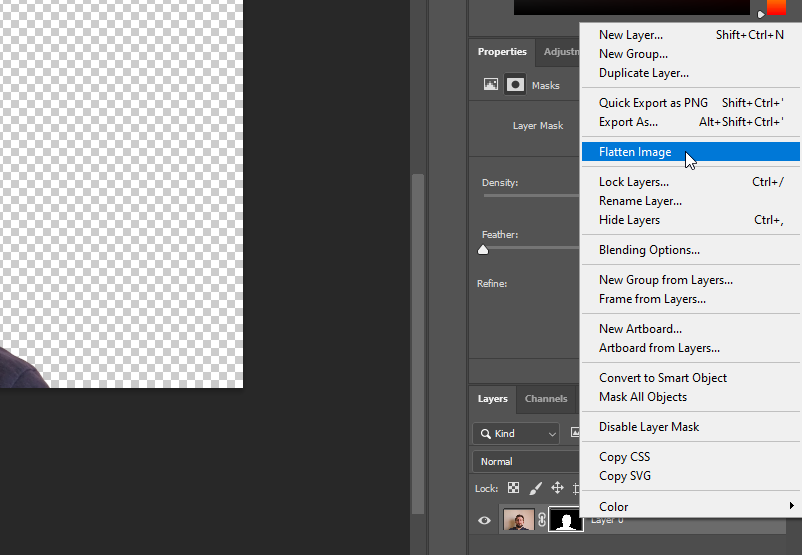
Todas nuestras acciones han sido registradas. Detengamos este proceso:
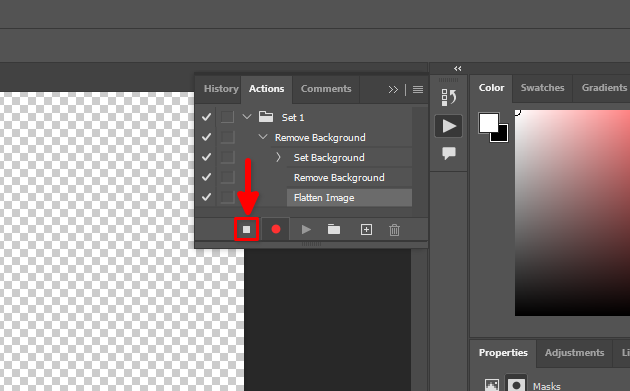
Ahora, puede cerrar el archivo abierto sin guardar los cambios y seleccionar File >> Scripts >> Image Processor…
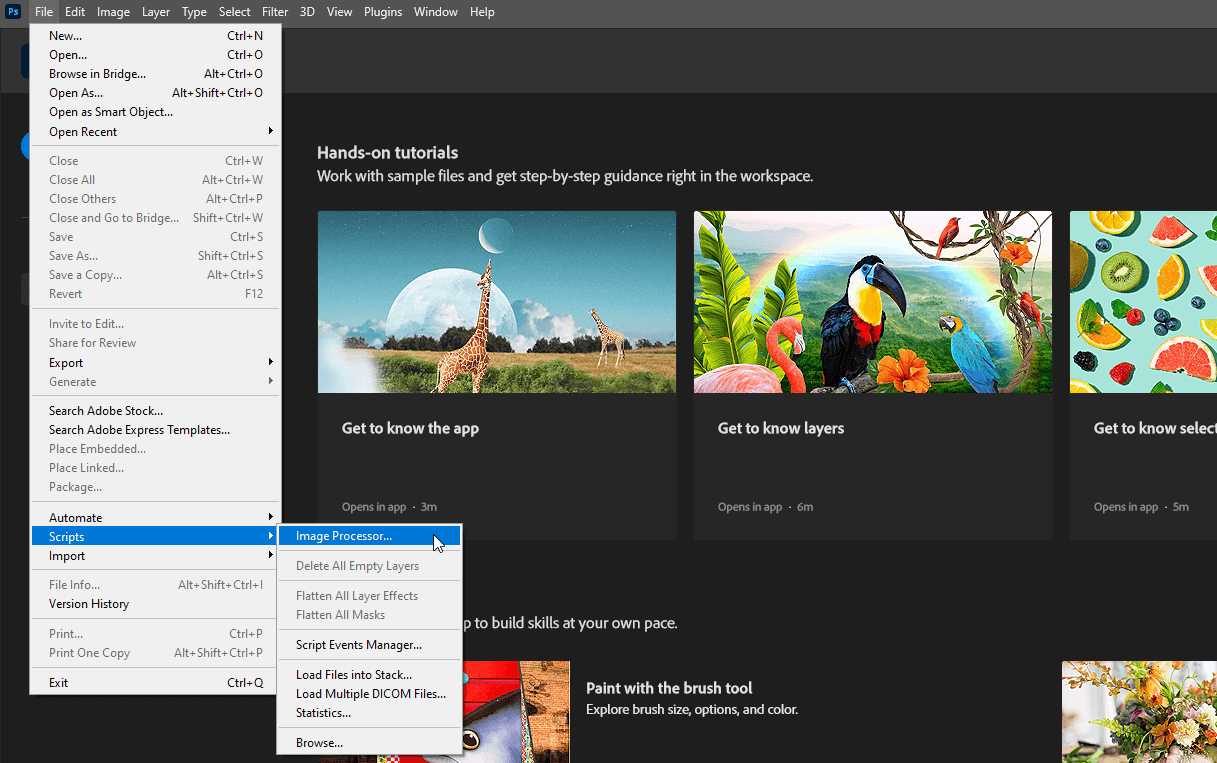
Seleccione los directorios de entrada y salida, elija la acción Remove Background creada en el paso 4 y haga clic en el botón Run:
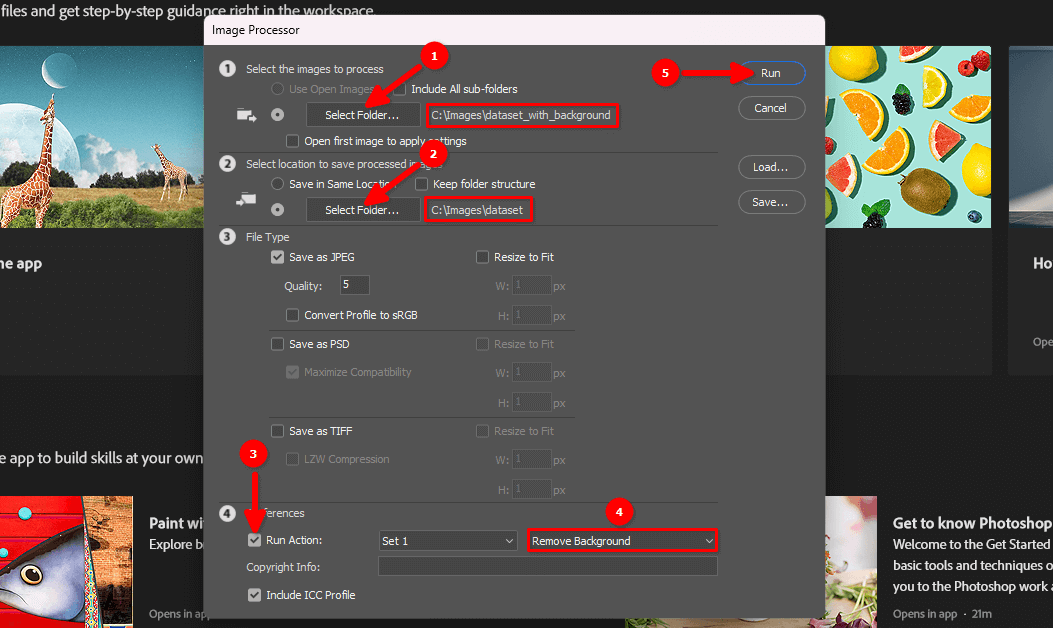
Tenga paciencia. Adobe Photoshop abrirá todas las imágenes del directorio seleccionado, repetirá las acciones grabadas (desactivar el bloqueo de capas, eliminar el fondo, aplanar la imagen) y las guardará en otro directorio seleccionado. Este proceso puede tardar un par de minutos, dependiendo del número de imágenes.

Una vez finalizado el proceso, puede pasar al siguiente paso.
Subir al servidor
Utilice una de las siguientes guías (adaptada al sistema operativo de su PC) para cargar el directorio dataset en el servidor remoto. Por ejemplo, colócalo en el directorio de inicio del usuario por defecto, /home/usergpu:
- Intercambio de archivos desde Linux
- Intercambio de archivos desde Windows
- Intercambio de archivos desde macOS
Preinstalación
Actualice los paquetes existentes del sistema:
sudo apt update && sudo apt -y upgradeInstale dos paquetes adicionales:
sudo apt install -y python3-tk python3.10-venvInstalemos el CUDA® Toolkit versión 11.8. Descarguemos el archivo pin específico:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinEl siguiente comando coloca el archivo descargado en el directorio del sistema, controlado por el gestor de paquetes apt:
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600El siguiente paso es descargar el repositorio principal de CUDA:
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.debDespués, proceda a la instalación del paquete utilizando la utilidad estándar dpkg:
sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.debCopie el llavero GPG en el directorio del sistema. Esto hará que esté disponible para su uso por las utilidades del sistema operativo, incluyendo el gestor de paquetes apt:
sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/Actualice los repositorios de caché del sistema:
sudo apt-get updateInstala el kit de herramientas CUDA® usando apt:
sudo apt-get -y install cudaAñade CUDA® a PATH. Abra la configuración de shell bash:
nano ~/.bashrcAñade las siguientes líneas al final del archivo:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}Guarde el archivo y reinicie el servidor:
sudo shutdown -r nowInstalar entrenador
Copie el repositorio del proyecto Kohya en el servidor:
git clone https://github.com/bmaltais/kohya_ss.gitAbra el directorio descargado:
cd kohya_ssHaz ejecutable el script de instalación:
chmod +x ./setup.shEjecuta el script:
./setup.shRecibirás un mensaje de advertencia de la utilidad de aceleración. Vamos a resolver el problema. Activa el entorno virtual del proyecto:
source venv/bin/activateInstala el paquete que falta:
pip install scipyY configura manualmente la utilidad de aceleración:
accelerate configTen cuidado, porque activar un número impar de CPUs causará un error. Por ejemplo, si tengo 5 GPUs, sólo se pueden utilizar 4 con este software. De lo contrario, se producirá un error al iniciar el proceso. Puede comprobar inmediatamente la nueva configuración de la utilidad llamando a una prueba predeterminada:
accelerate testSi todo está bien, recibirá un mensaje como este:
Test is a success! You are ready for your distributed training!
deactivateAhora, puedes iniciar el servidor público del entrenador con la GUI de Gradio y una simple autenticación de usuario/contraseña (cambia el usuario/contraseña por los tuyos):
./gui.sh --share --username user --password passwordRecibirás dos cadenas:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://.gradio.live
Abra su navegador web e introduzca la URL pública en la barra de direcciones. Escriba su nombre de usuario y contraseña en los campos correspondientes y, a continuación, haga clic en Iniciar sesión:
Preparar el conjunto de datos
Comience por crear una nueva carpeta en la que almacenará el modelo LoRA entrenado:
mkdir /home/usergpu/myloramodelAbre las siguientes pestañas: Utilities >> Captioning >> BLIP captioning. Rellena los huecos como se muestra en la imagen y haz clic en Caption images:
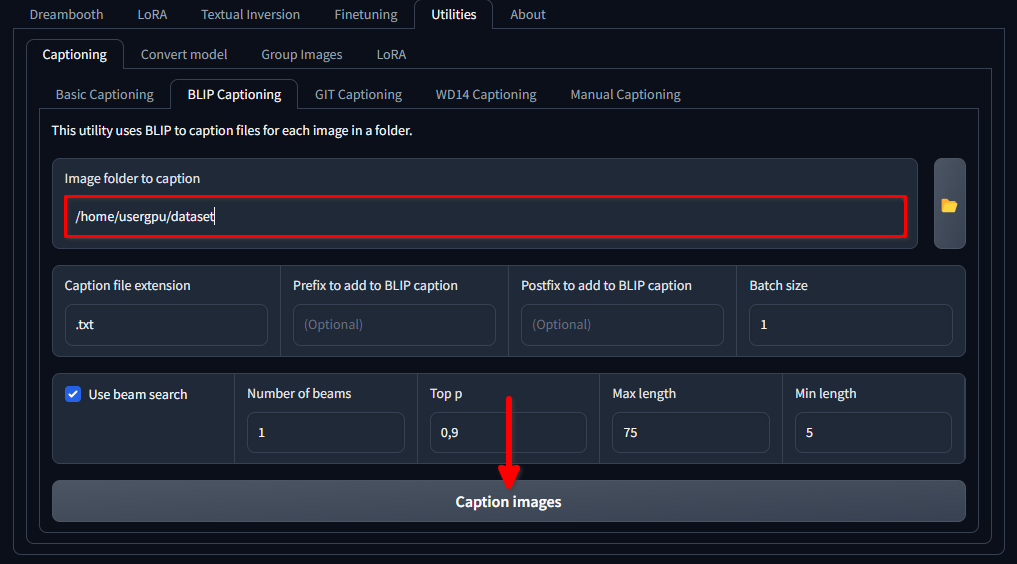
Trainer descargará y ejecutará un modelo de red neuronal específico (1,6 Gb) que crea mensajes de texto para cada archivo de imagen del directorio seleccionado. Se ejecutará en una sola GPU y tardará alrededor de un minuto.
Cambia la pestaña a LoRA >> Tools >> Dataset preparation >> Dreambooth/LoRA folder preparation, rellena los huecos y pulsa secuencialmente Prepare training data y Copy info to Folders Tab:
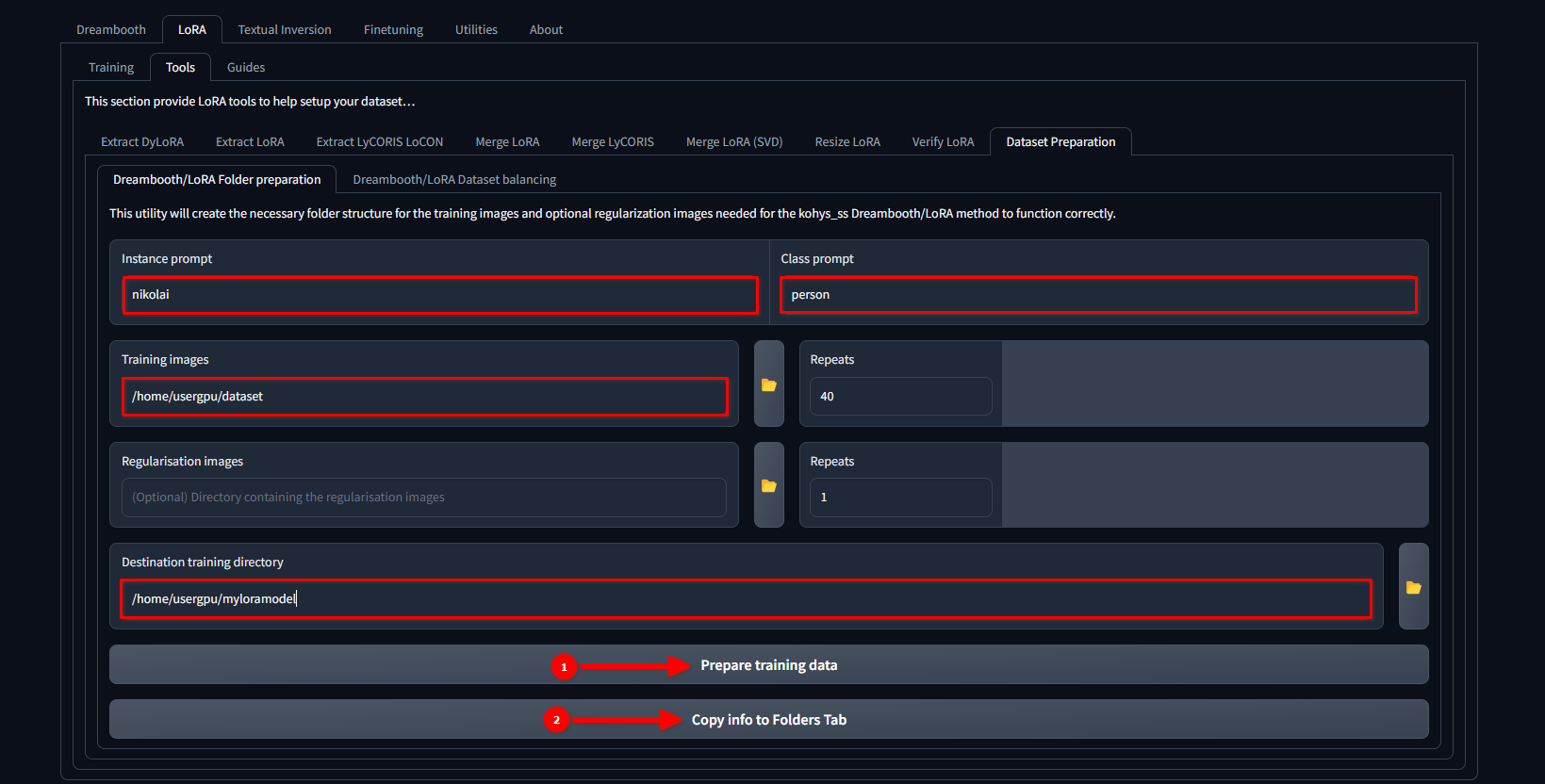
En este ejemplo, utilizamos el nombre nikolai como Instance prompt y "persona" como Class prompt. También establecemos /home/usergpu/dataset como Training Images y /home/usergpu/myloramodel como Destination training directory.
Cambie de nuevo a la pestaña LoRA >> Training >> Folders. Asegúrese de que Image folder, Output folder y Logging folder están correctamente rellenados. Si lo desea, puede cambiar el Model output name por el suyo propio. Por último, haga clic en el botón Start training:
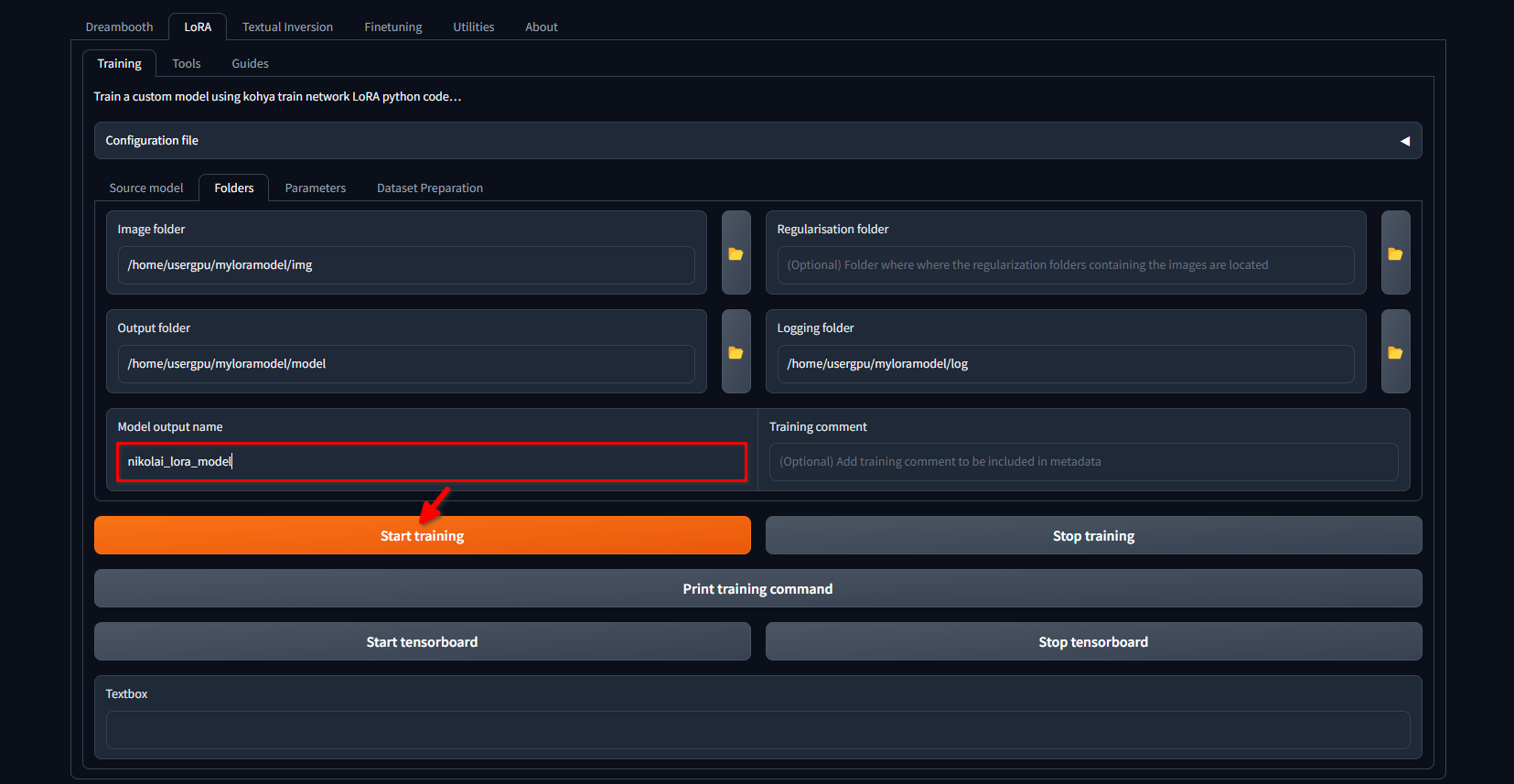
El sistema comenzará a descargar archivos y modelos adicionales (~10 GB). A continuación, comenzará el proceso de entrenamiento. Dependiendo de la cantidad de imágenes y de los ajustes aplicados, puede tardar varias horas. Una vez finalizado el entrenamiento, puede descargar el directorio /home/usergpu/myloramodel a su ordenador para utilizarlo en el futuro.
Pruebe su LoRA
Hemos preparado algunos artículos sobre Stable Diffusion y sus bifurcaciones. Puedes intentar instalar Easy Diffusion con nuestra guía Easy Diffusion UI. Después de que el sistema se haya instalado y esté funcionando, puedes subir tu modelo LoRA en formato SafeTensors directamente a /home/usergpu/easy-diffusion/models/lora
Actualiza la página web de Easy diffusion y selecciona tu modelo de la lista desplegable:
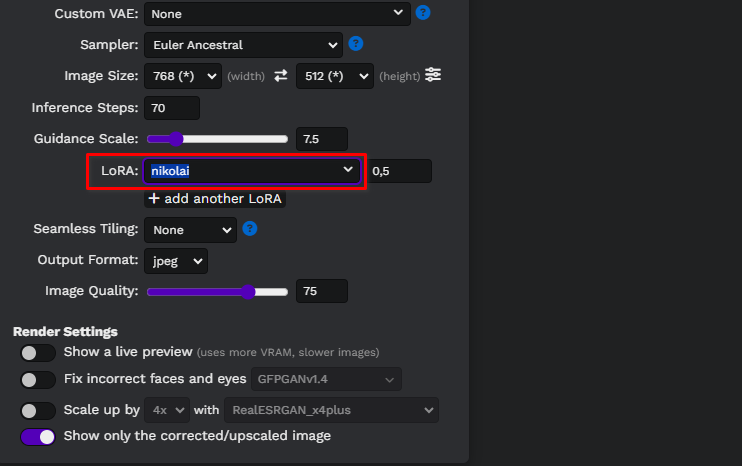
Vamos a escribir un simple mensaje, portrait of <nikolai> wearing a cowboy hat, y generar nuestras primeras imágenes. Aquí, usamos un modelo personalizado de Difusión Estable descargado de civitai.com: Realistic Vision v6.0 B1:
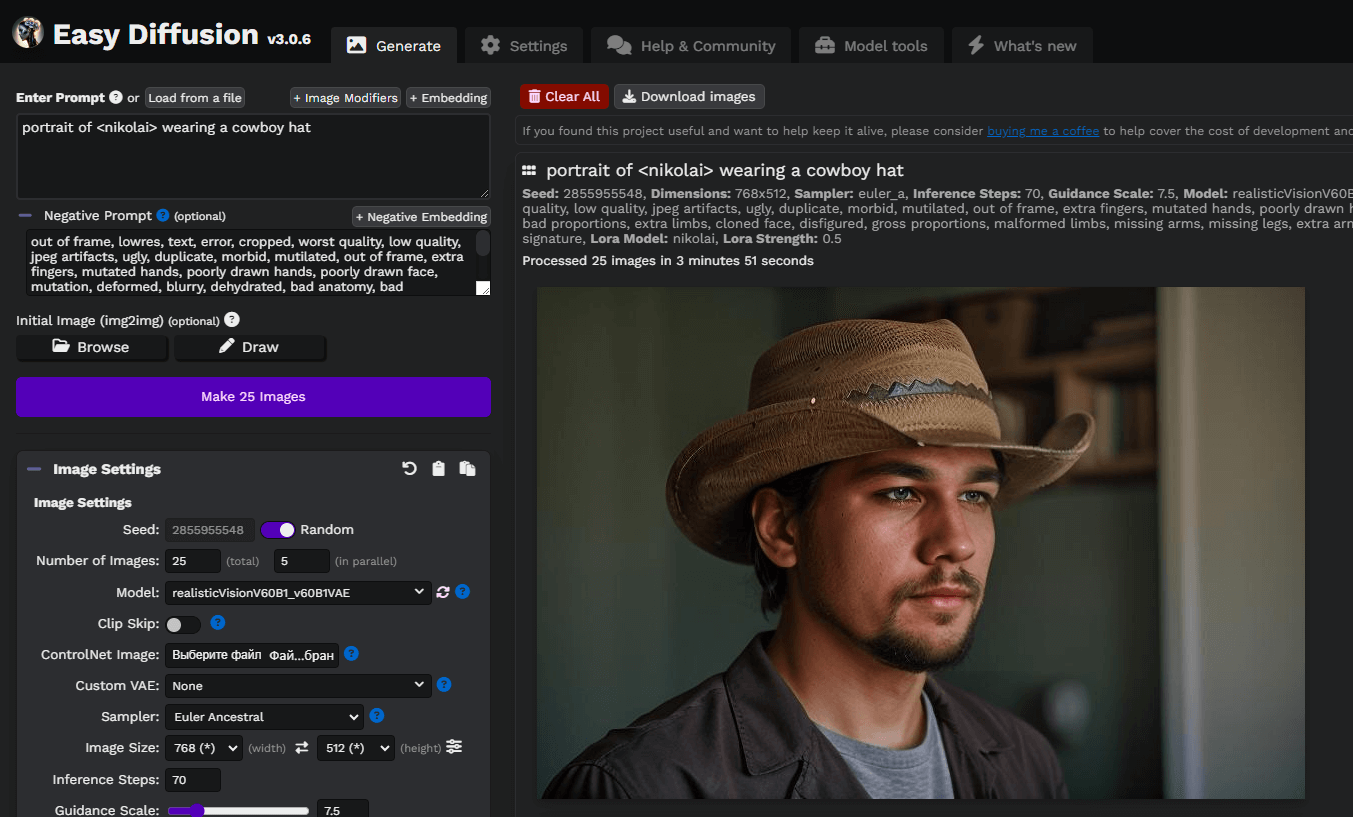
Puedes experimentar con instrucciones y modelos basados en Stable Diffusion para obtener mejores resultados. ¡Que aproveche!
Ver también:
Actualizado: 04.01.2026
Publicado: 21.01.2025




