





AudioCraft de MetaAI: crear música por descripción

Las redes neuronales generativas modernas son cada vez más inteligentes. Escriben historias, entablan conversaciones con la gente y crean imágenes ultrarrealistas. Ahora, pueden producir sencillas pistas de música sin necesidad de artistas profesionales. Este futuro ya es una realidad. Era de esperar, ya que las armonías y ritmos musicales tienen sus raíces en principios matemáticos.
Meta ha demostrado su compromiso con el mundo del software de código abierto. Han puesto a disposición del público tres modelos de redes neuronales que permiten crear sonidos y música a partir de descripciones de texto:
- MusicGen - genera música a partir de texto.
- AudioGen - genera audio a partir de texto.
- EnCodec - compresor neural de audio de alta calidad.
MusicGen fue entrenado en 20.000 horas de música. Puede utilizarlo localmente a través de servidores LeaderGPU dedicados como plataforma.
Instalación estándar
Actualice el repositorio de caché de paquetes:
sudo apt update && sudo apt -y upgradeInstale el gestor de paquetes de Python, pip, y las bibliotecas ffmpeg:
sudo apt -y install python3-pip ffmpegInstala torch 2.0 o más reciente usando pip:
pip install 'torch>=2.0'El siguiente comando instala automáticamente audiocraft y todas las dependencias necesarias:
pip install -U audiocraftVamos a escribir una sencilla aplicación Python, utilizando el gran modelo MusicGen pre-entrenado con 3.3B parámetros:
nano generate.pyfrom audiocraft.models import MusicGen
from audiocraft.data.audio import audio_write
model = MusicGen.get_pretrained("facebook/musicgen-large")
model.set_generation_params(duration=30) # generate a 30 seconds sample.
descriptions = ["rock solo"]
wav = model.generate(descriptions) # generates sample.
for idx, one_wav in enumerate(wav):
# Will save under {idx}.wav, with loudness normalization at -14 db LUFS.
audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness")Ejecuta la aplicación creada:
python3 generate.pyDespués de unos segundos, el archivo generado (0.wav) aparecerá en el directorio.
Café Vampir 3
Clonar un repositorio de proyecto:
git clone https://github.com/CoffeeVampir3/audiocraft-webui.gitAbre el directorio clonado:
cd audiocraft-webuiEjecuta el comando que prepara tu sistema e instala todos los paquetes necesarios:
pip install -r requirements.txtA continuación, ejecute el servidor Coffee Vampire 3 con el siguiente comando:
python3 webui.pyCoffee Vampire 3 utiliza Flask como framework. Por defecto, se ejecuta en localhost con el puerto 5000. Si desea acceso remoto, por favor utilice la función de redirección de puertos en su cliente SSH. De lo contrario, puede organizar la conexión VPN al servidor.
Atención. Se trata de una acción potencialmente peligrosa; utilícela bajo su propia responsabilidad:
nano webui.pyDesplácese hasta el final y sustituya socketio.run(app) por socketio.run(app, host=’0.0.0.0’, port=5000)
Guarde el archivo y ejecute el servidor utilizando el comando anterior. Esto permite el acceso al servidor desde la Internet pública sin ningún tipo de autenticación.
No olvides disable AdBlock software, ya que puede bloquear el reproductor de música a la derecha de la página web. Puedes empezar entrando en el prompt y confirmando con el botón Submit:
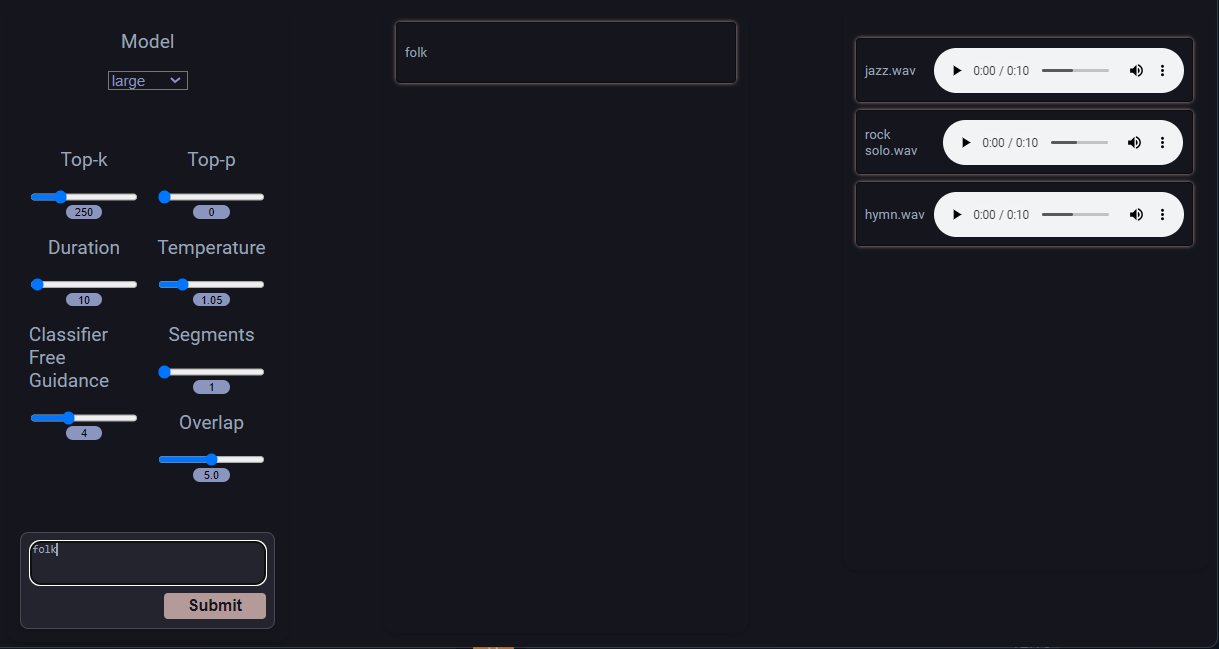
TTS Generation WebUI
Paso 1. Controladores
Actualice el repositorio de caché de paquetes:
sudo apt update && sudo apt -y upgradeInstale los controladores NVIDIA® usando el instalador automático o nuestra guía Instalar controladores NVIDIA® en Linux:
sudo ubuntu-drivers autoinstallReinicie el servidor:
sudo shutdown -r nowPaso 2. Docker
El siguiente paso es instalar Docker. Vamos a instalar algunos paquetes que hay que añadir al repositorio de Docker:
sudo apt -y install apt-transport-https curl gnupg-agent ca-certificates software-properties-commonDescarga la clave GPG de Docker y guárdala:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -Añade el repositorio:
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable"Instale Docker CE (Community Edition) con CLI y el runtime containerd:
sudo apt -y install docker-ce docker-ce-cli containerd.ioAñade el usuario actual al grupo docker:
sudo usermod -aG docker $USERAplicar los cambios sin el procedimiento de cierre de sesión e inicio de sesión:
newgrp dockerPaso 3. Paso de GPU
Vamos a habilitar NVIDIA® GPU passthrough en Docker. El siguiente comando lee la versión actual del sistema operativo en la variable de distribución, que podemos utilizar en el siguiente paso:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)Descarga la clave GPG del repositorio de NVIDIA® y guárdala:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -Descarga la lista de repositorios de NVIDIA® y almacénala para utilizarla en el gestor de paquetes estándar de APT:
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listActualiza el repositorio de caché de paquetes e instala el kit de herramientas GPU passthrough:
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkitReinicia el demonio Docker:
sudo systemctl restart dockerPaso 4. WebUI
Descargue el archivo del repositorio:
wget https://github.com/rsxdalv/tts-generation-webui/archive/refs/heads/main.zipDescomprímelo:
unzip main.zipAbre el directorio del proyecto:
cd tts-generation-webui-mainEmpieza a construir la imagen:
docker build -t rsxdalv/tts-generation-webui .Ejecuta el contenedor creado:
docker compose up -dAhora puede abrir http://[server_ip]:7860, escriba su consulta, seleccione el modelo necesario y pulse el botón Generate:
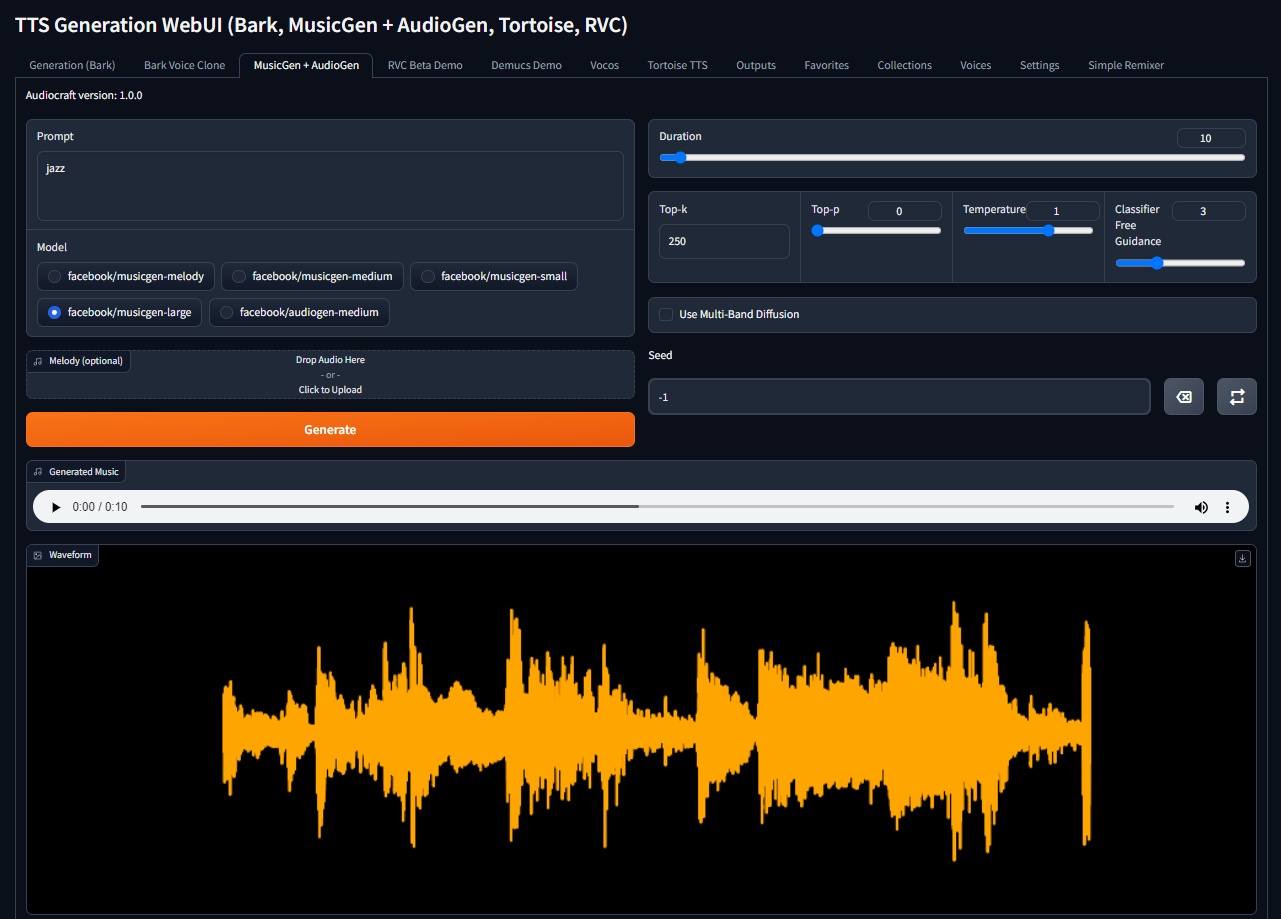
El sistema descarga automáticamente el modelo seleccionado durante la primera generación. ¡Que aproveche!
Ver también:
Actualizado: 04.01.2026
Publicado: 22.01.2025




