





DeepSeek-R1: el futuro de los LLM

Aunque las redes neuronales generativas se han desarrollado rápidamente, su progreso en los últimos años se ha mantenido bastante estable. Esto cambió con la llegada de DeepSeek, una red neuronal china que no sólo impactó en la bolsa, sino que captó la atención de desarrolladores e investigadores de todo el mundo. A diferencia de otros grandes proyectos, el código de DeepSeek se publicó bajo la permisiva licencia MIT. Este paso hacia el código abierto se ganó los elogios de la comunidad, que empezó a explorar con entusiasmo las capacidades del nuevo modelo.
El aspecto más impresionante fue que, al parecer, el entrenamiento de esta nueva red neuronal costó 20 veces menos que el de competidores que ofrecían una calidad similar. El modelo sólo necesitó 55 días y 5,6 millones de dólares para entrenarse. El lanzamiento de DeepSeek provocó una de las mayores caídas en un solo día de la historia del mercado bursátil estadounidense. Aunque los mercados acabaron estabilizándose, el impacto fue significativo.
Este artículo examinará la precisión con la que los titulares de los medios reflejan la realidad y explorará qué configuraciones de LeaderGPU son adecuadas para instalar usted mismo esta red neuronal.
Características arquitectónicas
DeepSeek ha elegido un camino de máxima optimización, lo que no es de extrañar dadas las restricciones a la exportación de China a Estados Unidos. Estas restricciones impiden que el país utilice oficialmente los modelos de GPU más avanzados para el desarrollo de IA.
El modelo emplea la tecnología Multi Token Prediction (MTP), que predice múltiples tokens en un solo paso de inferencia en lugar de uno solo. Esto funciona mediante la descodificación paralela de tokens combinada con capas especiales enmascaradas que mantienen la autorregresividad.
Las pruebas de MTP han mostrado resultados notables, aumentando la velocidad de generación entre 2 y 4 veces en comparación con los métodos tradicionales. La excelente escalabilidad de la tecnología la hace valiosa para aplicaciones actuales y futuras de procesamiento del lenguaje natural.
El modelo Multi-Head Latent Attention (MLA) presenta un mecanismo de atención mejorado. A medida que el modelo construye largas cadenas de razonamiento, mantiene la atención centrada en el contexto en cada etapa. Esta mejora le permite manejar mejor los conceptos abstractos y las dependencias textuales.
La característica clave de MLA es su capacidad para ajustar dinámicamente el peso de la atención a distintos niveles de abstracción. Al procesar consultas complejas, MLA examina los datos desde múltiples perspectivas: el significado de las palabras, la estructura de las frases y el contexto general. Estas perspectivas forman capas distintas que influyen en el resultado final. Para mantener la claridad, MLA equilibra cuidadosamente el impacto de cada capa sin perder de vista la tarea principal.
Los desarrolladores de DeepSeek incorporaron al modelo la tecnología de Mezcla de Expertos (MoE). Contiene 256 redes neuronales expertas preentrenadas, cada una especializada en tareas diferentes. El sistema activa 8 de estas redes para cada entrada de token, lo que permite un procesamiento eficiente de los datos sin aumentar los costes computacionales.
En el modelo completo con 671b parámetros, sólo se activan 37b para cada token. El modelo selecciona de forma inteligente los parámetros más relevantes para procesar cada ficha entrante. Esta eficiente optimización ahorra recursos computacionales al tiempo que mantiene un alto rendimiento.
Una característica crucial de cualquier chatbot de red neuronal es la longitud de su ventana de contexto. Llama 2 tiene un límite de contexto de 4.096 tokens, GPT-3.5 maneja 16.284 tokens, mientras que GPT-4 y DeepSeek pueden procesar hasta 128.000 tokens (unas 100.000 palabras, equivalentes a 300 páginas de texto mecanografiado).
R - Razonamiento
DeepSeek-R1 ha adquirido un mecanismo de razonamiento similar al de OpenAI o1, lo que le permite gestionar tareas complejas con mayor eficacia y precisión. En lugar de proporcionar respuestas inmediatas, el modelo amplía el contexto generando razonamientos paso a paso en pequeños párrafos. Este enfoque mejora la capacidad de la red neuronal para identificar relaciones complejas entre datos, lo que da lugar a respuestas más completas y precisas.
Cuando se enfrenta a una tarea compleja, DeepSeek utiliza su mecanismo de razonamiento para descomponer el problema en componentes y analizar cada uno por separado. A continuación, el modelo sintetiza estos resultados para generar una respuesta para el usuario. Aunque este parece ser un enfoque ideal para las redes neuronales, conlleva importantes retos.
Todas las LLM modernas comparten un rasgo preocupante: las alucinaciones artificiales. Cuando se le presenta una pregunta que no puede responder, en lugar de reconocer sus limitaciones, el modelo puede generar respuestas ficticias apoyadas en hechos inventados.
Cuando se aplican a una red neuronal de razonamiento, estas alucinaciones podrían comprometer el proceso de pensamiento al basar las conclusiones en información ficticia y no en hechos. Esto podría llevar a conclusiones incorrectas, un reto que los investigadores y desarrolladores de redes neuronales tendrán que abordar en el futuro.
Consumo de VRAM
Veamos cómo ejecutar y probar DeepSeek R1 en un servidor dedicado, centrándonos en los requisitos de memoria de vídeo de la GPU.
| Modelo | VRAM (Mb) | Tamaño del modelo (Gb) |
|---|---|---|
| deepseek-r1:1.5b | 1,952 | 1.1 |
| deepseek-r1:7b | 5,604 | 4.7 |
| deepseek-r1:8b | 6,482 | 4.9 |
| deepseek-r1:14b | 10,880 | 9 |
| deepseek-r1:32b | 21,758 | 20 |
| deepseek-r1:70b | 39,284 | 43 |
| deepseek-r1:671b | 470,091 | 404 |
Las tres primeras opciones (1.5b, 7b, 8b) son modelos básicos que pueden realizar la mayoría de las tareas de forma eficiente. Estos modelos funcionan sin problemas en cualquier GPU de consumo con 6-8 GB de memoria de vídeo. Las versiones intermedias (14b y 32b) son ideales para tareas profesionales, pero requieren más VRAM. Los modelos más grandes (70b y 671b) requieren GPU especializadas y se utilizan principalmente para aplicaciones industriales y de investigación.
Selección de servidores
Para ayudarte a elegir un servidor para la inferencia DeepSeek, aquí tienes las configuraciones LeaderGPU ideales para cada grupo de modelos:
1,5b / 7b / 8b / 14b / 32b / 70b
Para este grupo, cualquier servidor con los siguientes tipos de GPU será adecuado. La mayoría de los servidores LeaderGPU ejecutarán estas redes neuronales sin problemas. El rendimiento dependerá principalmente del número de núcleos CUDA®. Recomendamos servidores con múltiples GPUs, tales como:
671b
Ahora pasemos al caso más difícil: ¿cómo ejecutar la inferencia en un modelo con un tamaño base de 404 GB? Esto significa que se necesitarán aproximadamente 470 GB de memoria de vídeo. LeaderGPU ofrece múltiples configuraciones con las siguientes GPU capaces de manejar esta carga:
Ambas configuraciones gestionan la carga del modelo de forma eficiente, distribuyéndola uniformemente entre varias GPU. Por ejemplo, este es el aspecto de un servidor con 8xH100 después de cargar el modelo deepseek-r1:671b:
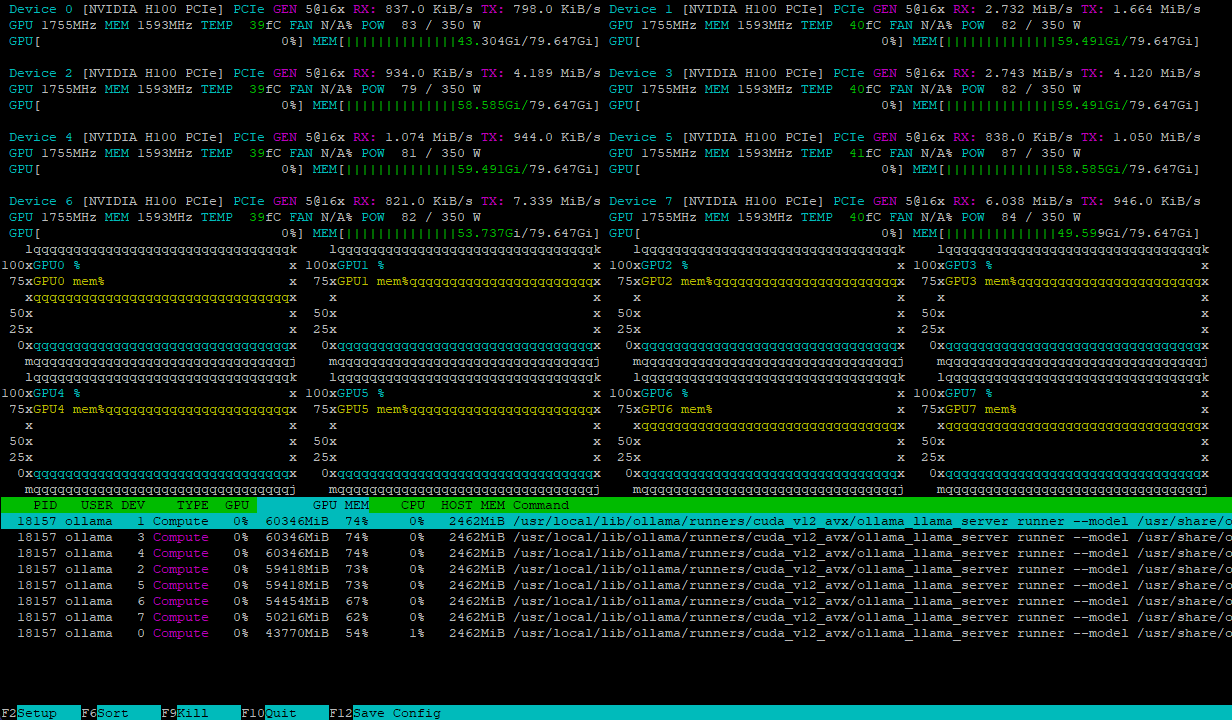
La carga computacional se equilibra dinámicamente entre las GPU, mientras que las interconexiones NVLink® de alta velocidad evitan los cuellos de botella en el intercambio de datos, garantizando el máximo rendimiento.
Conclusión
DeepSeek-R1 combina muchas tecnologías innovadoras como la predicción multitoken, la atención latente multicabeza y la mezcla de expertos en un modelo significativo. Este software de código abierto demuestra que los LLM pueden desarrollarse de forma más eficiente con menos recursos computacionales. El modelo tiene varias versiones, desde la más pequeña de 1,5b hasta la enorme de 671b, que requieren hardware especializado con múltiples GPU de gama alta trabajando en paralelo.
Al alquilar un servidor de LeaderGPU para la inferencia de DeepSeek-R1, obtendrá una amplia gama de configuraciones, fiabilidad y tolerancia a fallos. Nuestro equipo de soporte técnico le ayudará con cualquier problema o pregunta, mientras que la instalación automática del sistema operativo reduce el tiempo de implementación.
Elija su servidor LeaderGPU y descubra las posibilidades que se abren al utilizar modernos modelos de redes neuronales. Si tiene alguna pregunta, no dude en formularla en nuestro chat o por correo electrónico.
Actualizado: 04.01.2026
Publicado: 19.02.2025




