





Creador de aplicaciones de inteligencia artificial de código reducido Langflow
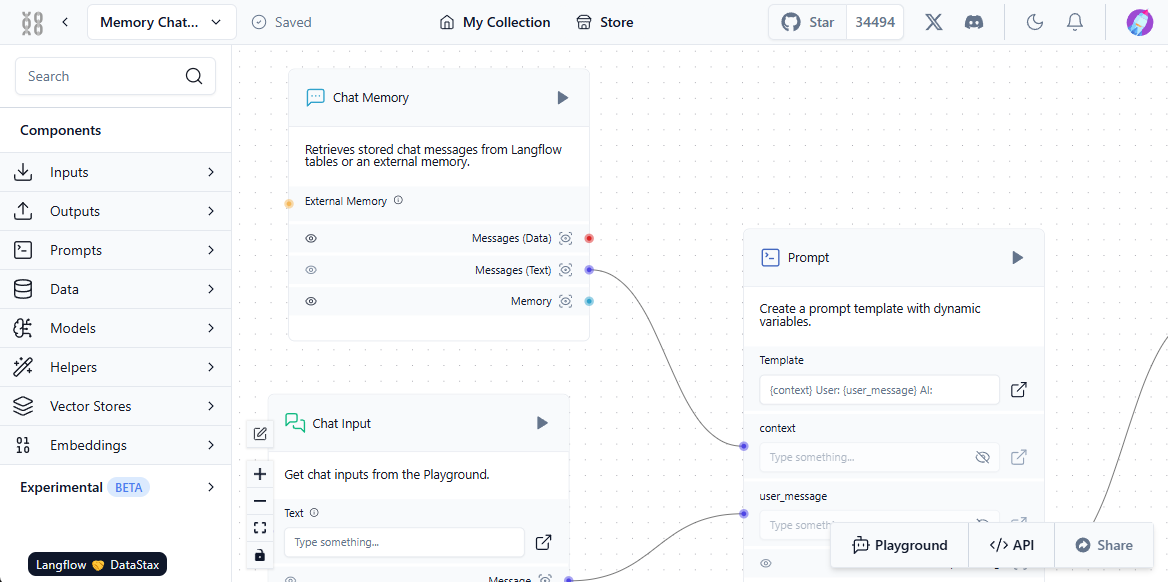
El desarrollo de software ha evolucionado espectacularmente en los últimos años. Los programadores modernos tienen ahora acceso a cientos de lenguajes y marcos de programación. Más allá de los enfoques imperativos y declarativos tradicionales, está surgiendo un nuevo y apasionante método de creación de aplicaciones. Este enfoque innovador aprovecha el poder de las redes neuronales, abriendo fantásticas posibilidades a los desarrolladores.
La gente se ha acostumbrado a que los asistentes de IA de los IDE ayuden a autocompletar el código y a que las redes neuronales modernas generen fácilmente código para juegos sencillos en Python. Sin embargo, están surgiendo nuevas herramientas híbridas que podrían revolucionar el panorama del desarrollo. Una de ellas es Langflow.
Langflow sirve para múltiples propósitos. Para los desarrolladores profesionales, ofrece un mejor control de sistemas complejos como las redes neuronales. Para quienes no están familiarizados con la programación, permite crear aplicaciones sencillas pero prácticas. Estos objetivos se logran a través de diferentes medios, que exploraremos con más detalle.
Redes neuronales
El concepto de red neuronal puede simplificarse para los usuarios. Imagine una caja negra que recibe datos de entrada y parámetros que influyen en el resultado final. Esta caja procesa la entrada utilizando algoritmos complejos, a menudo denominados "mágicos", y produce datos de salida que pueden presentarse al usuario.
El funcionamiento interno de esta caja negra varía en función del diseño de la red neuronal y de los datos de entrenamiento. Es fundamental comprender que los desarrolladores y los usuarios nunca pueden alcanzar una certeza del 100% en los resultados. A diferencia de la programación tradicional, en la que 2 + 2 siempre es igual a 4, una red neuronal puede dar esta respuesta con un 99% de certeza, manteniendo siempre un margen de error.
El control sobre el proceso de "pensamiento" de una red neuronal es indirecto. Sólo podemos ajustar ciertos parámetros, como la "temperatura". Este parámetro determina lo creativa o limitada que puede ser la red neuronal en su planteamiento. Un valor bajo de temperatura limita la red a un enfoque más formal y estructurado de las tareas y soluciones. Por el contrario, los valores altos de temperatura conceden más libertad a la red, lo que puede llevarla a basarse en hechos menos fiables o incluso a crear información ficticia.
Este ejemplo ilustra cómo los usuarios pueden influir en el resultado final. Para la programación tradicional, esta incertidumbre plantea un reto importante: los errores pueden aparecer de forma inesperada y los resultados concretos se vuelven impredecibles. Sin embargo, esta imprevisibilidad es sobre todo un problema para los ordenadores, no para los humanos, que pueden adaptarse a resultados variables e interpretarlos.
Si la salida de una red neuronal está destinada a un ser humano, la redacción específica utilizada para describirla suele ser menos importante. Dado el contexto, las personas pueden interpretar correctamente diversos resultados desde la perspectiva de la máquina. Mientras que conceptos como "valor positivo", "resultado obtenido" o "decisión positiva" pueden significar más o menos lo mismo para una persona, la programación tradicional tendría problemas con esta flexibilidad. Tendría que tener en cuenta todas las posibles variaciones de respuesta, lo cual es casi imposible.
En cambio, si el procesamiento posterior se transfiere a otra red neuronal, ésta puede entender y procesar correctamente el resultado obtenido. A partir de ahí, puede llegar a su propia conclusión con un cierto grado de confianza, como ya se ha dicho.
Código bajo
La mayoría de los lenguajes de programación implican escribir código. Los programadores crean mentalmente la lógica de cada parte de una aplicación y luego la describen mediante expresiones específicas del lenguaje. Este proceso forma un algoritmo: una secuencia Clara™ de acciones que conducen a un resultado específico y predeterminado. Es una tarea compleja que requiere un gran esfuerzo mental y un profundo conocimiento de las posibilidades del lenguaje.
Sin embargo, no es necesario reinventar la rueda. Muchos de los problemas a los que se enfrentan los desarrolladores modernos ya se han resuelto de diversas maneras. A menudo se pueden encontrar fragmentos de código relevantes en StackOverflow. La programación moderna puede compararse con el ensamblaje de un todo a partir de piezas de diferentes juegos de construcción. El sistema Lego ofrece un modelo de éxito, al haber estandarizado diferentes conjuntos de piezas para garantizar la compatibilidad.
El método de programación de bajo código sigue un principio similar. Se modifican varias piezas de código para que encajen a la perfección y se presentan a los desarrolladores como bloques listos para usar. Cada bloque puede tener entradas y salidas de datos. La documentación especifica la tarea que resuelve cada tipo de bloque y el formato en que acepta o emite datos.
Al conectar estos bloques en una secuencia específica, los desarrolladores pueden formar el algoritmo de una aplicación y visualizar claramente su lógica operativa. Quizá el ejemplo más conocido de este método de programación sea el de los gráficos de tortuga, utilizado habitualmente en entornos educativos para introducir conceptos de programación y desarrollar el pensamiento algorítmico.
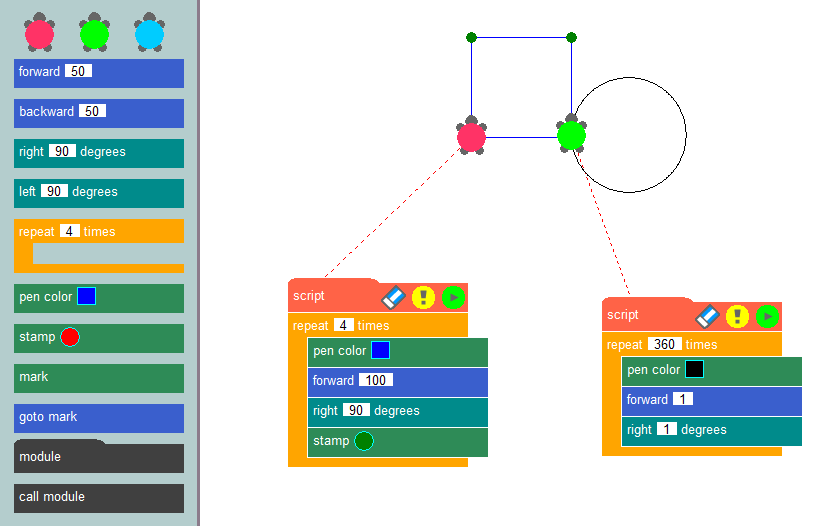
La esencia de este método es simple: dibujar imágenes en la pantalla utilizando una tortuga virtual que deja un rastro mientras se arrastra por el lienzo. Utilizando bloques prefabricados, como mover un número determinado de píxeles, girar en ángulos específicos o subir y bajar el lápiz, los desarrolladores pueden crear programas que dibujen las imágenes que deseen. La creación de aplicaciones mediante un constructor de bajo código es similar a los gráficos de tortuga, pero permite a los usuarios resolver una amplia gama de problemas, no sólo dibujar sobre un lienzo.
Este método se implementó mejor en la herramienta de programación Node-RED de IBM. Se desarrolló como medio universal para garantizar el funcionamiento conjunto de diversos dispositivos, servicios en línea y API. El equivalente de los fragmentos de código eran nodos de la biblioteca estándar (paleta).

Las capacidades de Node-RED pueden ampliarse instalando complementos o creando nodos personalizados que realicen acciones de datos específicas. Los desarrolladores colocan los nodos de la paleta en el escritorio y establecen relaciones entre ellos. Este proceso crea la lógica de la aplicación, y la visualización ayuda a mantener la claridad.
Si a este concepto se añaden las redes neuronales, se obtiene un sistema fascinante. En lugar de procesar los datos con fórmulas matemáticas específicas, puedes introducirlos en una red neuronal y especificar la salida deseada. Aunque los datos de entrada pueden variar ligeramente cada vez, los resultados siguen siendo aptos para ser interpretados por humanos u otras redes neuronales.
Generación Aumentada de Recuperación (RAG)
La precisión de los datos en los grandes modelos lingüísticos es una preocupación acuciante. Estos modelos se basan únicamente en los conocimientos adquiridos durante el entrenamiento, que depende de la relevancia de los conjuntos de datos utilizados. En consecuencia, los modelos lingüísticos de gran tamaño pueden carecer de suficientes datos pertinentes, lo que puede dar lugar a resultados incorrectos.
Para resolver este problema, se necesitan métodos de actualización de datos. Permitir que las redes neuronales extraigan contexto de fuentes adicionales, como páginas web, puede mejorar notablemente la calidad de las respuestas. Así es como funciona precisamente RAG (Retrieval-Augmented Generation). Los datos adicionales se convierten en representaciones vectoriales y se almacenan en una base de datos.
En funcionamiento, los modelos de redes neuronales pueden convertir las peticiones de los usuarios en representaciones vectoriales y compararlas con las almacenadas en la base de datos. Cuando se encuentran vectores similares, se extraen los datos y se utilizan para formar una respuesta. Las bases de datos vectoriales son lo bastante rápidas para soportar este esquema en tiempo real.
Para que este sistema funcione correctamente, debe establecerse una interacción entre el usuario, el modelo de red neuronal, las fuentes de datos externas y la base de datos vectorial. Langflow simplifica esta configuración con su componente visual: los usuarios simplemente construyen bloques estándar y los "enlazan", creando una ruta para el flujo de datos.
El primer paso consiste en poblar la base de datos vectorial con las fuentes pertinentes. Éstas pueden incluir archivos de un ordenador local o páginas web de Internet. He aquí un sencillo ejemplo de carga de datos en la base de datos:
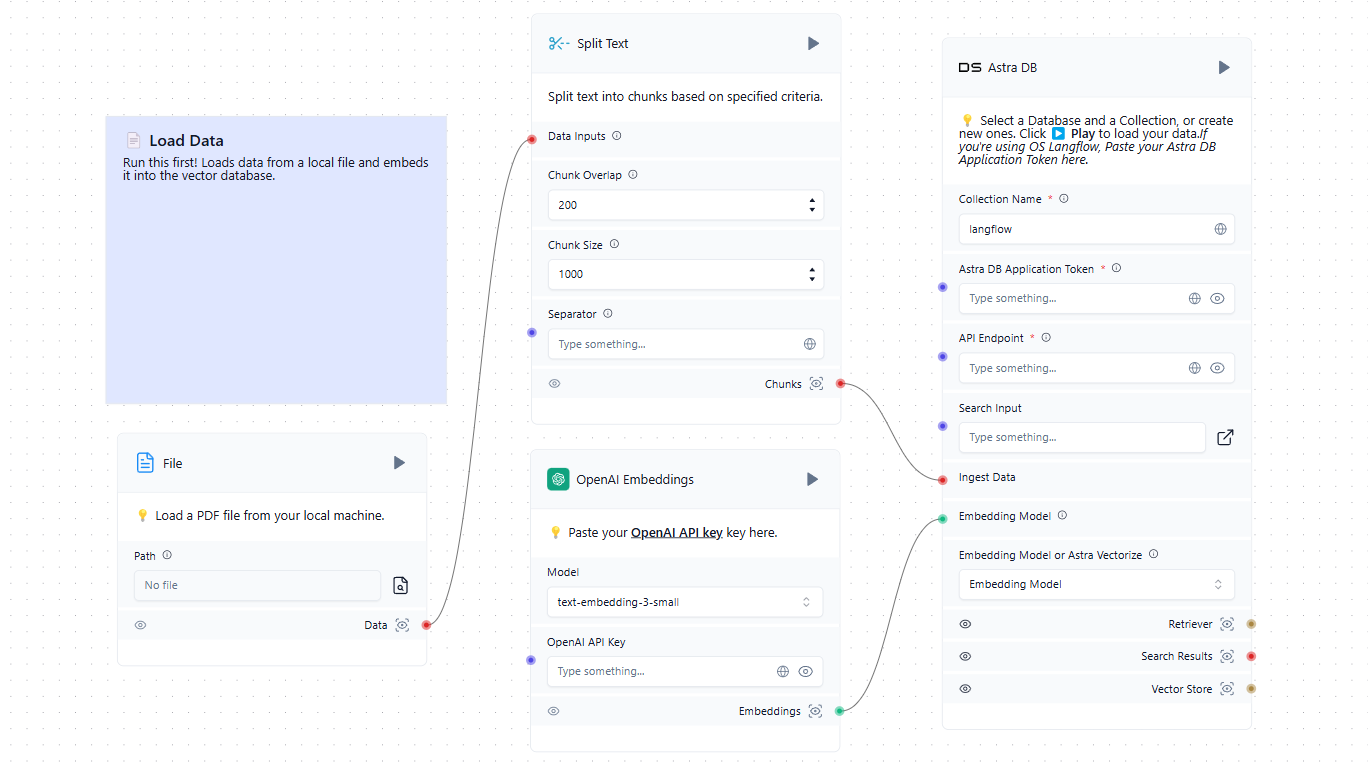
Ahora que tenemos una base de datos vectorial además del LLM entrenado, podemos incorporarla al esquema general. Cuando un usuario envía una petición en el chat, éste forma simultáneamente una petición y consulta la base de datos de vectores. Si se encuentran vectores similares, los datos extraídos se analizan y se añaden como contexto a la solicitud formada. A continuación, el sistema envía una petición a la red neuronal y emite la respuesta recibida al usuario en el chat.
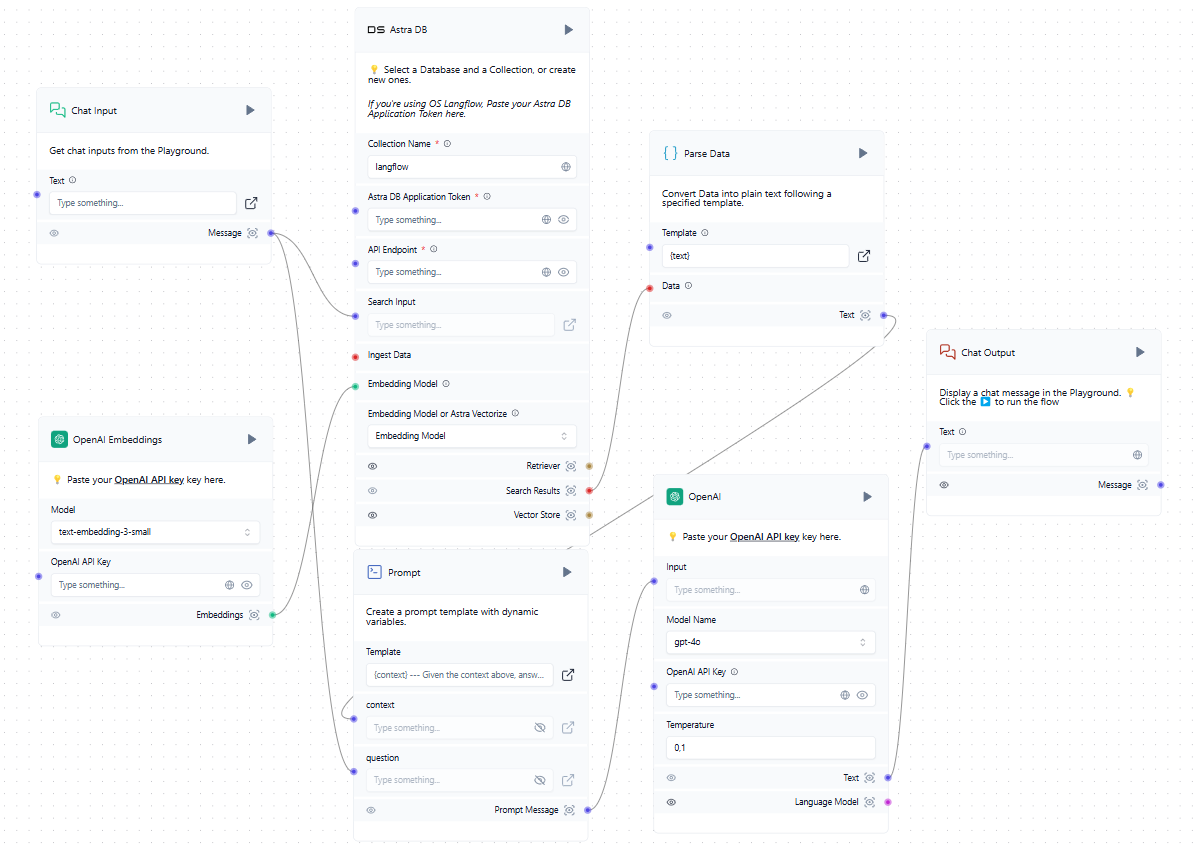
Aunque el ejemplo menciona servicios en la nube como OpenAI y AstraDB, puedes utilizar cualquier servicio compatible, incluidos los desplegados localmente en servidores LeaderGPU. Si no encuentras la integración que necesitas en la lista de bloques disponibles, puedes escribirla tú mismo o añadir una creada por otra persona.
Inicio rápido
Preparación del sistema
La forma más sencilla de desplegar Langflow es dentro de un contenedor Docker. Para configurar el servidor, comience por instalar Docker Engine. A continuación, actualice tanto la caché de paquetes como los paquetes a sus últimas versiones:
sudo apt update && sudo apt -y upgradeInstale los paquetes adicionales requeridos por Docker:
sudo apt -y install apt-transport-https ca-certificates curl software-properties-commonDescarga la clave GPG para añadir el repositorio oficial de Docker:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgAñade el repositorio a APT utilizando la clave que descargaste e instalaste anteriormente:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullActualice la lista de paquetes:
sudo apt updatePara asegurarte de que Docker se instalará desde el repositorio recién añadido y no desde el del sistema, puedes ejecutar el siguiente comando:
apt-cache policy docker-ceInstalar motor Docker:
sudo apt install docker-ceCompruebe que Docker se ha instalado correctamente y que el demonio correspondiente se está ejecutando y se encuentra en el estado active (running):
sudo systemctl status docker● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset>
Active: active (running) since Mon 2024-11-18 08:26:35 UTC; 3h 27min ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 1842 (dockerd)
Tasks: 29
Memory: 1.8G
CPU: 3min 15.715s
CGroup: /system.slice/docker.service
Construir y ejecutar
Todo está listo para construir y ejecutar un contenedor Docker con Langflow. Sin embargo, hay una advertencia: en el momento de escribir esta guía, la última versión (etiquetada v1.1.0) tiene un error y no se inicia. Para evitar este problema, vamos a utilizar la versión anterior, v1.0.19.post2, que funciona perfectamente después de la descarga.
Lo más sencillo es descargar el repositorio del proyecto desde GitHub:
git clone https://github.com/langflow-ai/langflowNavega hasta el directorio que contiene la configuración de despliegue de ejemplo:
cd langflow/docker_exampleAhora tendrá que hacer dos cosas. Primero, cambiar la etiqueta release para que se construya una versión funcional (en el momento de escribir estas instrucciones). En segundo lugar, añada una autorización simple para que nadie pueda utilizar el sistema sin conocer el nombre de usuario y la contraseña.
Abra el archivo de configuración:
sudo nano docker-compose.ymlen lugar de la siguiente línea:
image: langflowai/langflow:latestespecifique la versión en lugar de la etiqueta latest:
image: langflowai/langflow:v1.0.19.post2También debe añadir tres variables a la sección environment:
- LANGFLOW_AUTO_LOGIN=false
- LANGFLOW_SUPERUSER=admin
- LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordLa primera variable desactiva el acceso a la interfaz web sin autorización. La segunda añade el nombre de usuario que recibirá derechos de administrador del sistema. La tercera añade la contraseña correspondiente.
Si tiene previsto almacenar el archivo docker-compose.yml en un sistema de control de versiones, evite escribir la contraseña directamente en este archivo. En su lugar, cree un archivo independiente con extensión .env en el mismo directorio y almacene allí el valor de la variable.
LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordEn el archivo docker-compose.yml, ahora puede hacer referencia a una variable en lugar de especificar directamente una contraseña:
LANGFLOW_SUPERUSER_PASSWORD=${LANGFLOW_SUPERUSER_PASSWORD}Para evitar exponer accidentalmente el archivo *.env en GitHub, recuerda añadirlo a .gitignore. Esto mantendrá tu contraseña razonablemente a salvo de accesos no deseados.
Ahora, todo lo que queda es construir nuestro contenedor y ejecutarlo:
sudo docker compose upAbre la página web en http://[LeaderGPU_IP_address]:7860, y verás el formulario de autorización:
Una vez que introduzcas tu nombre de usuario y contraseña, el sistema te dará acceso a la interfaz web donde podrás crear tus propias aplicaciones. Para una orientación más detallada, le sugerimos que consulte la documentación oficial. En ella se ofrecen detalles sobre diversas variables de entorno que permiten personalizar fácilmente el sistema para adaptarlo a sus necesidades.
Ver también:
Actualizado: 04.01.2026
Publicado: 22.01.2025




