





Triton™ Inference Server

Los requisitos empresariales pueden variar, pero todos comparten un principio básico: los sistemas deben funcionar con rapidez y ofrecer la máxima calidad posible. Cuando se trata de la inferencia de redes neuronales, el uso eficiente de los recursos computacionales se convierte en algo crucial. Cualquier infrautilización de la GPU o tiempo de inactividad se traduce directamente en pérdidas económicas.
Consideremos un mercado como ejemplo. Estas plataformas alojan numerosos productos, cada uno con múltiples atributos: descripciones de texto, especificaciones técnicas, categorías y contenido multimedia como fotos y vídeos. Todo el contenido requiere moderación para mantener unas condiciones justas para los vendedores y evitar que aparezcan en la plataforma productos prohibidos o contenidos ilegales.
Aunque la moderación manual es posible, resulta lenta e ineficaz. En un entorno tan competitivo como el actual, los vendedores necesitan ampliar su gama de productos con rapidez: cuanto más rápido aparezcan los artículos en el mercado, más posibilidades tendrán de ser descubiertos y comprados. La moderación manual también es costosa y propensa a errores humanos, lo que puede permitir la publicación de contenidos inapropiados.
La moderación automática mediante redes neuronales especialmente entrenadas ofrece una solución. Este enfoque aporta múltiples ventajas: reduce sustancialmente los costes de moderación al tiempo que suele mejorar la calidad. Las redes neuronales procesan los contenidos mucho más rápido que los humanos, lo que permite a los vendedores superar la fase de moderación con mayor rapidez, especialmente cuando se manejan grandes volúmenes de productos.
Sin embargo, este método tiene sus dificultades. La moderación automatizada requiere desarrollar y entrenar modelos de redes neuronales, lo que exige personal cualificado y recursos informáticos considerables. Sin embargo, las ventajas se aprecian rápidamente tras la implantación inicial. La implantación automatizada de modelos puede agilizar considerablemente las operaciones en curso.
Inferencia
Supongamos que hemos resuelto los procedimientos de aprendizaje automático. El siguiente paso es determinar cómo ejecutar la inferencia del modelo en un servidor alquilado. Para un único modelo, normalmente se elige una herramienta que funcione bien con el marco específico en el que se creó. Sin embargo, cuando se trata de múltiples modelos creados en diferentes marcos, tiene dos opciones.
Puedes convertir todos los modelos a un único formato, o elegir una herramienta que soporte múltiples marcos. Triton™ Inference Server encaja perfectamente con el segundo enfoque. Soporta los siguientes backends:
- TensorRT™
- TensorRT-LLM
- vLLM
- Python
- PyTorch (LibTorch)
- ONNX Runtime
- Tensorflow
- FIL
- DALI
Además, puede utilizar cualquier aplicación como backend. Por ejemplo, si necesitas post-procesamiento con una aplicación C/C++, puedes integrarla sin problemas.
Escalado
Triton™ Inference Server gestiona eficientemente los recursos computacionales de un único servidor ejecutando múltiples modelos simultáneamente y distribuyendo la carga de trabajo entre las GPUs.
La instalación se realiza a través de un contenedor Docker. Los ingenieros de DevOps pueden controlar la asignación de GPU al inicio, eligiendo utilizar todas las GPU o limitar su número. Aunque el software no gestiona directamente el escalado horizontal, se pueden utilizar balanceadores de carga tradicionales como HAproxy o desplegar aplicaciones en un clúster Kubernetes con este fin.
Preparación del sistema
Para configurar Triton™ en un servidor LeaderGPU con Ubuntu 22.04, primero actualiza el sistema utilizando este comando:
sudo apt update && sudo apt -y upgradeEn primer lugar, instala los controladores NVIDIA® utilizando el script de autoinstalación:
sudo ubuntu-drivers autoinstallReinicia el servidor para aplicar los cambios:
sudo shutdown -r nowUna vez que el servidor vuelva a estar en línea, instale Docker utilizando el siguiente script de instalación:
curl -sSL https://get.docker.com/ | shComo Docker no puede pasar GPUs a contenedores por defecto, necesitarás el NVIDIA® Container Toolkit. Añade el repositorio de NVIDIA® descargando y registrando su clave GPG:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listActualiza la caché de paquetes e instala el kit de herramientas:
sudo apt update && sudo apt -y install nvidia-container-toolkitReinicia Docker para habilitar las nuevas capacidades:
sudo systemctl restart dockerEl sistema operativo ya está listo para su uso.
Instalación del servidor de inferencia Triton™
Vamos a descargar el repositorio del proyecto:
git clone https://github.com/triton-inference-server/serverEste repositorio contiene ejemplos de redes neuronales preconfiguradas y un script de descarga de modelos. Navega hasta el directorio examples:
cd server/docs/examplesDescargue los modelos ejecutando el siguiente script, que los guardará en ~/server/docs/examples/model_repository:
./fetch_models.shLa arquitectura del Servidor de Inferencia Triton™ requiere que los modelos se almacenen por separado. Puedes almacenarlos localmente en cualquier directorio del servidor o en almacenamiento en red. Al iniciar el servidor, tendrás que montar este directorio en el contenedor en el punto de montaje /models. Esto sirve como repositorio para todas las versiones de los modelos.
Inicie el contenedor con este comando
sudo docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ~/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:25.01-py3 tritonserver --model-repository=/modelsEsto es lo que hace cada parámetro
- --gpus=all especifica que se utilizarán todas las GPUs disponibles en el servidor;
- --rm destruye el contenedor una vez finalizado o detenido el proceso;
- -p8000:8000 reenvía el puerto 8000 para recibir peticiones HTTP;
- -p8001:8001 reenvía el puerto 8001 para recibir peticiones gRPC;
- -p8002:8002 reenvía el puerto 8002 para solicitar métricas;
- -v ~/server/docs/examples/model_repository:/models reenvía el directorio con modelos
- nvcr.io/nvidia/tritonserver:25.01-py3 dirección del contenedor del catálogo NGC;
- tritonserver --model-repository=/models lanza el Servidor de Inferencia Triton™ con la ubicación del repositorio de modelos en /models.
La salida del comando mostrará todos los modelos disponibles en el repositorio, cada uno listo para aceptar peticiones:
+----------------------+---------+--------+ | Model | Version | Status | +----------------------+---------+--------+ | densenet_onnx | 1 | READY | | inception_graphdef | 1 | READY | | simple | 1 | READY | | simple_dyna_sequence | 1 | READY | | simple_identity | 1 | READY | | simple_int8 | 1 | READY | | simple_sequence | 1 | READY | | simple_string | 1 | READY | +----------------------+---------+--------+
Los tres servicios se han lanzado con éxito en los puertos 8000, 8001 y 8002:
I0217 08:00:34.930188 1 grpc_server.cc:2466] Started GRPCInferenceService at 0.0.0.0:8001 I0217 08:00:34.930393 1 http_server.cc:4636] Started HTTPService at 0.0.0.0:8000 I0217 08:00:34.972340 1 http_server.cc:320] Started Metrics Service at 0.0.0.0:8002
Usando la utilidad nvtop, podemos verificar que todas las GPUs están listas para aceptar la carga:
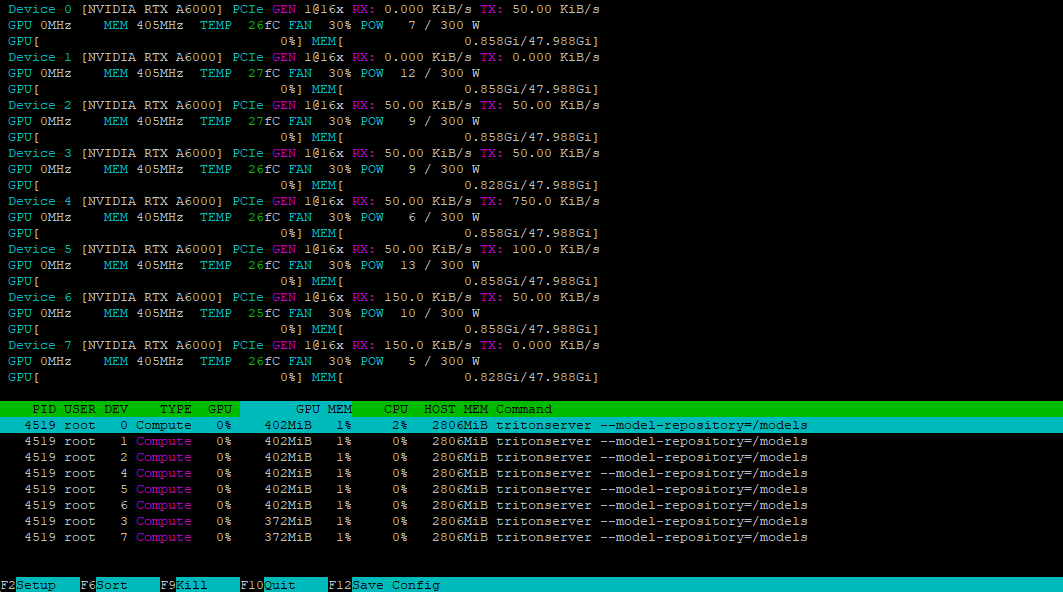
Instalación del cliente
Para acceder a nuestro servidor, necesitaremos generar una petición apropiada utilizando el cliente incluido en el SDK. Podemos descargar este SDK como un contenedor Docker:
sudo docker pull nvcr.io/nvidia/tritonserver:25.01-py3-sdkEjecuta el contenedor en modo interactivo para acceder a la consola:
sudo docker run -it --gpus=all --rm --net=host nvcr.io/nvidia/tritonserver:25.01-py3-sdkVamos a probarlo con el modelo DenseNet en formato ONNX, utilizando el método INCEPTION para preprocesar y analizar la imagen mug.jpg:
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpgEl cliente contactará con el servidor, que creará un lote y lo procesará utilizando las GPUs disponibles del contenedor. Este es el resultado:
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.349562 (504) = COFFEE MUG
13.227461 (968) = CUP
10.424891 (505) = COFFEEPOTPreparando el repositorio
Para que Triton™ gestione los modelos correctamente, debes preparar el repositorio de una manera específica. Esta es la estructura de directorios:
model_repository/
└── your_model/
├── config.pbtxt
└── 1/
└── model.*
Cada modelo necesita su propio directorio que contenga un archivo de configuración config.pbtxt con su descripción. He aquí un ejemplo:
name: "Test"
platform: "pytorch_libtorch"
max_batch_size: 8
input [
{
name: "INPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]En este ejemplo, un modelo llamado Test se ejecutará en el backend PyTorch. El parámetro max_batch_size establece el número máximo de elementos que se pueden procesar simultáneamente, lo que permite un equilibrio de carga eficiente entre los recursos. Establecer este valor a cero desactiva el procesamiento por lotes, haciendo que el modelo procese las peticiones secuencialmente.
El modelo acepta una entrada y produce una salida, ambas utilizando el tipo de número FP32. Los parámetros deben coincidir exactamente con los requisitos del modelo. Para el procesamiento de imágenes, una especificación de dimensión típica es dims: [ 3, 224, 224 ], donde:
- 3 - número de canales de color (RGB);
- 224 - altura de la imagen en píxeles;
- 224 - anchura de la imagen en píxeles.
La salida dims: [ 1000 ] representa un vector unidimensional de 1000 elementos, que se adapta a las tareas de clasificación de imágenes. Para determinar la dimensionalidad correcta para su modelo, consulte su documentación. Si el archivo de configuración está incompleto, Triton™ intentará generar automáticamente los parámetros que falten.
Iniciar un modelo personalizado
Vamos a lanzar la inferencia del modelo DeepSeek-R1 destilado del que hemos hablado antes. En primer lugar, crearemos la estructura de directorios necesaria:
mkdir ~/model_repository && mkdir ~/model_repository/deepseek && mkdir ~/model_repository/deepseek/1Navegue hasta el directorio del modelo:
cd ~/model_repository/deepseekCree un archivo de configuración config.pbtxt:
nano config.pbtxtPegue lo siguiente:
# Copyright 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of NVIDIA CORPORATION nor the names of its
# contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Note: You do not need to change any fields in this configuration.
backend: "vllm"
# The usage of device is deferred to the vLLM engine
instance_group [
{
count: 1
kind: KIND_MODEL
}
]Guarde el archivo pulsando Ctrl + O, luego el editor con Ctrl + X. Navegue hasta el directorio 1:
cd 1Cree un fichero de configuración del modelo model.json con los siguientes parámetros:
{
"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"disable_log_requests": true,
"gpu_memory_utilization": 0.9,
"enforce_eager": true
}Ten en cuenta que el valor de gpu_memory_utilization varía según la GPU y debe determinarse experimentalmente. Para esta guía, utilizaremos 0.9. Su estructura de directorios dentro de ~/model_repository ahora debe tener este aspecto:
└── deepseek
├── 1
│ └── model.json
└── config.pbtxt
Establece la variable LOCAL_MODEL_REPOSITORY por conveniencia:
LOCAL_MODEL_REPOSITORY=~/model_repository/Inicie el servidor de inferencia con este comando:
sudo docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 tritonserver --model-repository=model_repository/Esto es lo que hace cada parámetro:
- --rm elimina automáticamente el contenedor tras detenerse;
- -it ejecuta el contenedor en modo interactivo con salida de terminal;
- --net utiliza la pila de red del host en lugar del aislamiento del contenedor;
- --shm-size=2g establece la memoria compartida en 2 GB;
- --ulimit memlock=-1 elimina el límite de bloqueo de memoria;
- --ulimit stack=67108864 fija el tamaño de la pila en 64 MB;
- --gpus all habilita el acceso a todas las GPU del servidor;
- -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository monta el directorio del modelo local en el contenedor;
- nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 especifica el contenedor con soporte vLLM backend;
- tritonserver --model-repository=model_repository/ lanza el Servidor de Inferencia Triton™ con la ubicación del repositorio de modelos en model_repository.
Prueba el servidor enviando una petición con curl, utilizando un prompt simple y un límite de respuesta de 4096 tokens:
curl -X POST localhost:8000/v2/models/deepseek/generate -d '{"text_input": "Tell me about the Netherlands?", "max_tokens": 4096}'El servidor recibe y procesa la petición con éxito.
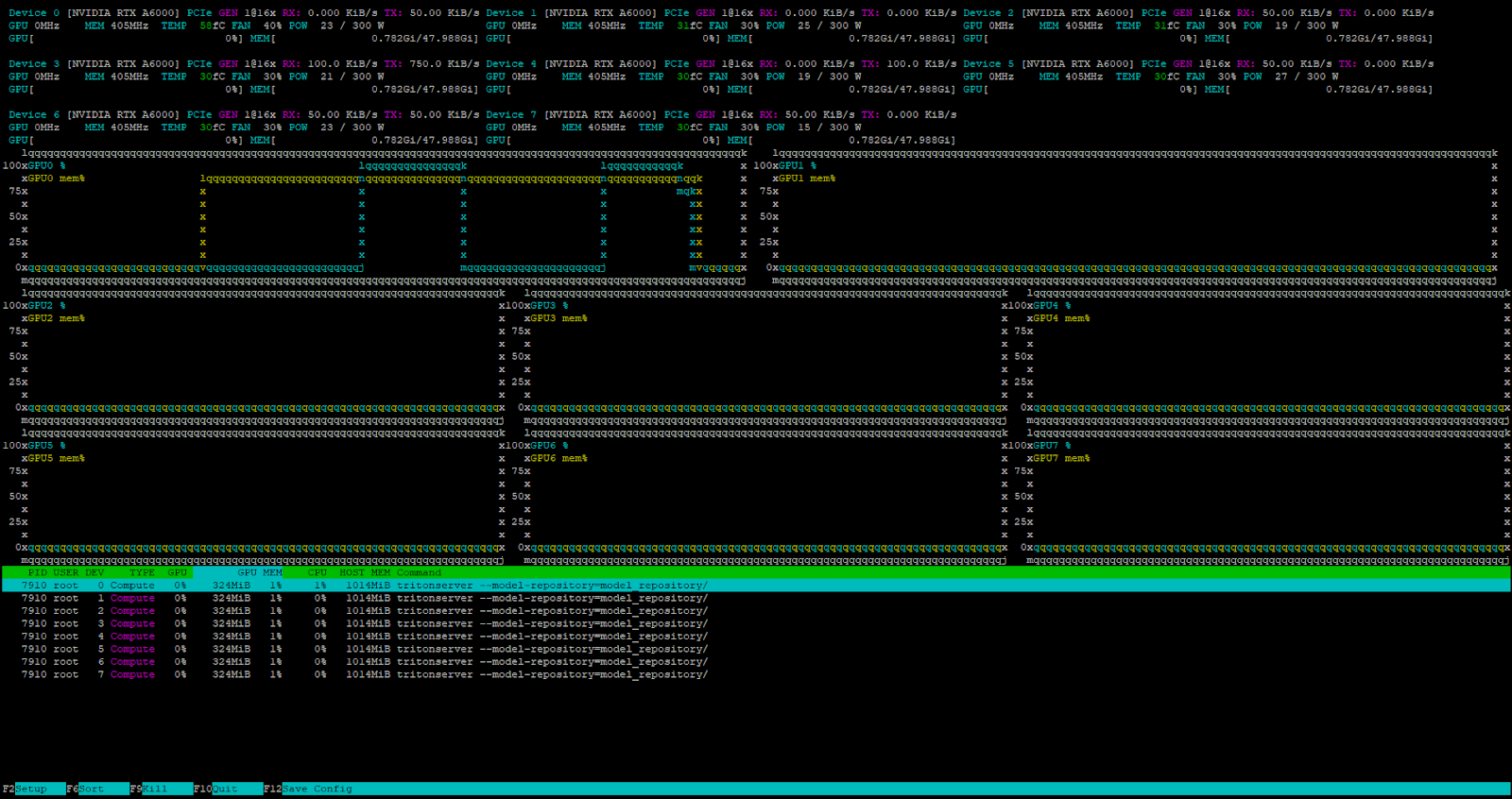
El programador de tareas interno de Triton™ gestiona todas las peticiones entrantes cuando el servidor está bajo carga.
Conclusión
El Servidor de Inferencia Triton™ destaca en el despliegue de modelos de aprendizaje automático en producción al distribuir eficientemente las peticiones entre las GPUs disponibles. Esto maximiza el uso de los recursos del servidor alquilado y reduce los costes de la infraestructura informática. El software funciona con varios backends, incluido vLLM para modelos lingüísticos de gran tamaño.
Dado que se instala como un contenedor Docker, puede integrarse fácilmente en cualquier canal CI/CD moderno. Pruébelo usted mismo alquilando un servidor de LeaderGPU.
Actualizado: 04.01.2026
Publicado: 26.02.2025




