





¿Cómo funciona Ollama?

Ollama es una herramienta para ejecutar localmente grandes modelos de redes neuronales. El uso de servicios públicos suele ser percibido por las empresas como un riesgo potencial de fuga de datos confidenciales y sensibles. Por ello, desplegar LLM en un servidor controlado permite gestionar de forma independiente los datos depositados en él, al tiempo que se aprovechan los puntos fuertes de LLM.
Esto también ayuda a evitar la desagradable situación de "vendor lock-in", en la que cualquier servicio público puede dejar de prestar servicios unilateralmente. Por supuesto, el objetivo inicial es permitir el uso de redes neuronales generativas en lugares donde no hay acceso a Internet o éste es difícil (por ejemplo, en un avión).
La idea era simplificar el lanzamiento, control y puesta a punto de las LLM. En lugar de complejas instrucciones de varios pasos, Ollama permite ejecutar un simple comando y recibir el resultado final al cabo de un tiempo. Se presentará simultáneamente en forma de modelo de red neuronal local, con el que podrá comunicarse mediante una interfaz web y una API para integrarlo fácilmente en otras aplicaciones.
Para muchos desarrolladores, esto se convirtió en una herramienta muy útil, ya que en la mayoría de los casos era posible integrar Ollama con el IDE utilizado y recibir recomendaciones o código ya escrito directamente mientras se trabajaba en la aplicación.
En un principio, Ollama estaba destinado únicamente a ordenadores con el sistema operativo macOS, pero más tarde fue portado a Linux y Windows. También se ha lanzado una versión especial para trabajar en entornos contenerizados como Docker. Actualmente, funciona igual de bien tanto en ordenadores de sobremesa como en cualquier servidor dedicado con una GPU. Ollama admite la posibilidad de cambiar entre distintos modelos de forma inmediata y maximiza todos los recursos disponibles. Por supuesto, estos modelos pueden no rendir tan bien en un escritorio normal, pero funcionan bastante adecuadamente.
Cómo instalar Ollama
Ollama puede instalarse de dos maneras: sin utilizar la contenedorización, mediante un script de instalación, y como un contenedor Docker ya preparado. El primer método facilita la gestión de los componentes del sistema y los modelos instalados, pero es menos tolerante a fallos. El segundo método es más tolerante a fallos, pero al utilizarlo hay que tener en cuenta todos los aspectos inherentes a los contenedores: una gestión algo más compleja y un enfoque diferente del almacenamiento de datos.
Independientemente del método elegido, se necesitan varios pasos adicionales para preparar el sistema operativo.
Requisitos previos
Actualizar el repositorio caché de paquetes y los paquetes instalados:
sudo apt update && sudo apt -y upgradeInstale todos los controladores de GPU necesarios utilizando la función de instalación automática:
sudo ubuntu-drivers autoinstallReinicie el servidor:
sudo shutdown -r nowInstalación mediante script
El siguiente script detecta la arquitectura actual del sistema operativo e instala la versión adecuada de Ollama:
curl -fsSL https://ollama.com/install.sh | shDurante la operación, el script creará un usuario ollama separado, bajo el cual se lanzará el demonio correspondiente. Por cierto, el mismo script funciona bien en WSL2, permitiendo la instalación de la versión Linux de Ollama en Windows Server.
Instalación mediante Docker
Existen varios métodos para instalar el motor Docker en un servidor. La forma más sencilla es utilizar un script específico que instale la versión actual de Docker. Este método es eficaz para Ubuntu Linux, desde la versión 20.04 (LTS) hasta la última versión, Ubuntu 24.04 (LTS):
curl -sSL https://get.docker.com/ | shPara que los contenedores Docker interactúen correctamente con la GPU, es necesario instalar un kit de herramientas adicional. Dado que no está disponible en los repositorios básicos de Ubuntu, es necesario añadir primero un repositorio de terceros mediante el siguiente comando:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listActualizar el repositorio caché de paquetes:
sudo apt updateE instala el paquete nvidia-container-toolkit:
sudo apt install nvidia-container-toolkitNo olvides reiniciar el demonio docker a través de systemctl:
sudo systemctl restart dockerEs hora de descargar y ejecutar Ollama con la interfaz web Open-WebUI:
sudo docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaAbra el navegador web y navegue a http://[server-ip]:3000:
Descargar y ejecutar los modelos
A través de la línea de comandos
Basta con ejecutar el siguiente comando:
ollama run llama3A través de WebUI
Abra Settings > Models, escriba el nombre del modelo necesario, por ejemplo, llama3 y haga clic en el botón con el símbolo de descarga:

El modelo se descargará e instalará automáticamente. Una vez completada, cierra la ventana de configuración y selecciona el modelo descargado. A continuación, podrás iniciar un diálogo con él:

Integración de VSCode
Si ha instalado Ollama utilizando el script de instalación, podrá ejecutar cualquiera de los modelos soportados casi al instante. En el siguiente ejemplo, ejecutaremos el modelo por defecto esperado por la extensión Ollama Autocoder (openhermes2.5-mistral:7b-q4_K_M):
ollama run openhermes2.5-mistral:7b-q4_K_MPor defecto, Ollama permite trabajar a través de una API, permitiendo únicamente conexiones desde el host local. Por lo tanto, antes de instalar y utilizar la extensión para Visual Studio Code, es necesario redireccionar puertos. En concreto, es necesario redirigir el puerto remoto 11434 al equipo local. Puede encontrar un ejemplo de cómo hacerlo en nuestro artículo sobre Easy Diffusion WebUI.
Escriba Ollama Autocoder en el campo de búsqueda y haga clic en Install:
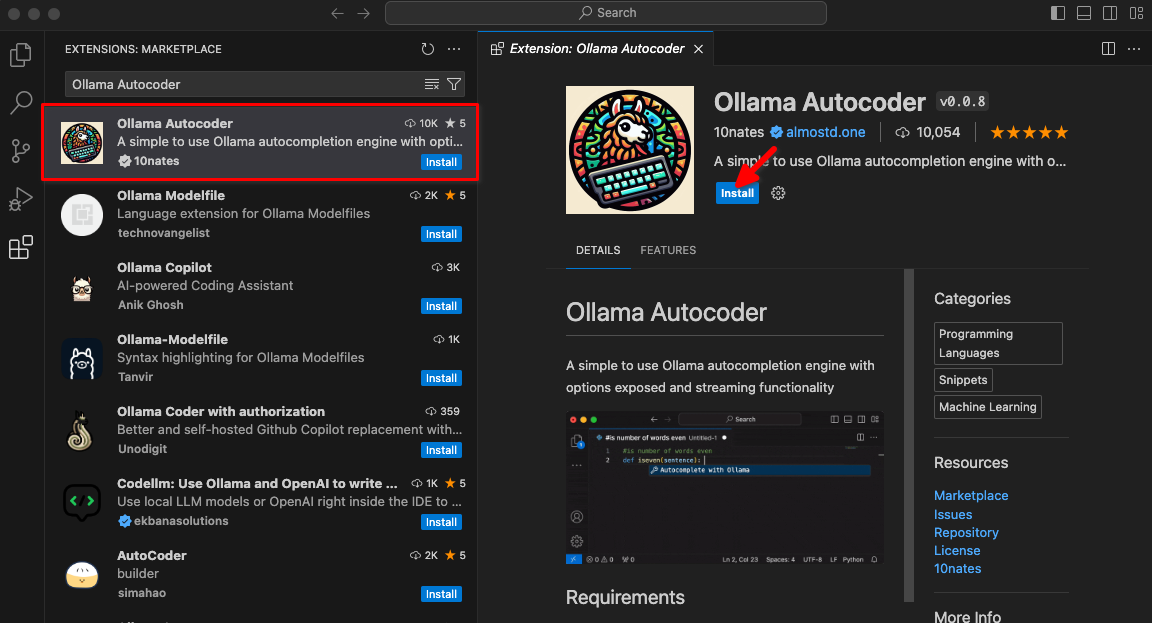
Después de instalar la extensión, un nuevo elemento titulado Autocomplete with Ollama estará disponible en la paleta de comandos. Comience a codificar e inicie este comando.
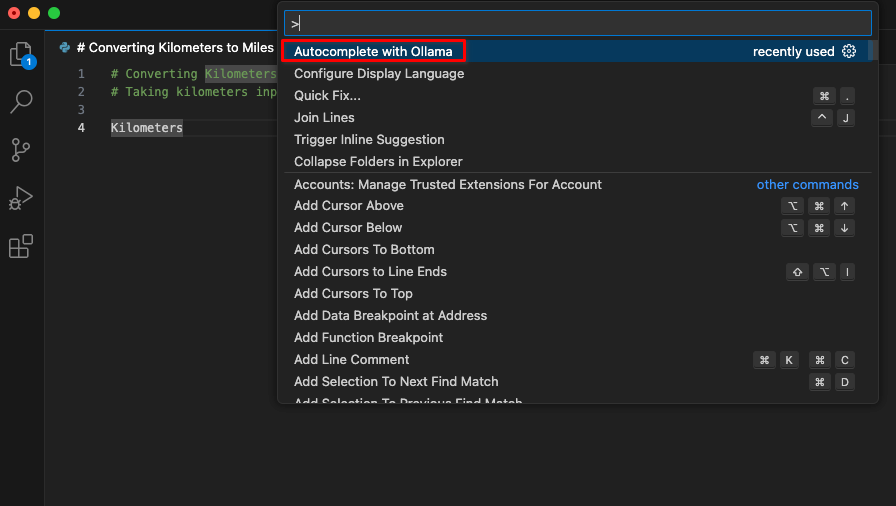
La extensión se conectará al servidor LeaderGPU utilizando el reenvío de puertos y, en unos segundos, el código generado aparecerá en su pantalla:
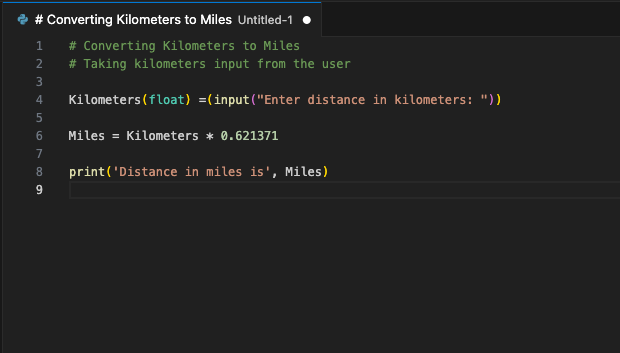
Puede asignar este comando a una tecla de acceso rápido. Utilízalo siempre que quieras complementar tu código con un fragmento generado. Éste es sólo un ejemplo de las extensiones VSCode disponibles. El principio del reenvío de puertos desde un servidor remoto a un ordenador local permite configurar un único servidor con un LLM en ejecución para todo un equipo de desarrolladores. Esta garantía impide que terceras empresas o piratas informáticos utilicen el código enviado.
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




