





Llama 3 usando Hugging Face

El 18 de abril de 2024 se lanzó el último gran modelo lingüístico de MetaAI, Llama 3. Se presentaron dos versiones a los usuarios: 8B y 70B. La primera versión contiene más de 15.000 tokens y fue entrenada con datos válidos hasta marzo de 2023. La segunda versión, más amplia, se entrenó con datos válidos hasta diciembre de 2023.
Paso 1. Preparar el sistema operativo Preparar el sistema operativo
Actualizar caché y paquetes
Vamos a actualizar la caché de paquetes y actualizar tu sistema operativo antes de empezar a configurar LLaMa 3. Ten en cuenta que para esta guía, estamos utilizando Ubuntu 22.04 LTS como sistema operativo:
sudo apt update && sudo apt -y upgradeAdemás, necesitamos añadir Python Installer Packages (PIP), si no está ya presente en el sistema:
sudo apt install python3-pipInstalar controladores NVIDIA®
Puedes utilizar la utilidad automatizada que se incluye por defecto en las distribuciones de Ubuntu:
sudo ubuntu-drivers autoinstallAlternativamente, puedes instalar los controladores NVIDIA® manualmente. No olvides reiniciar el servidor:
sudo shutdown -r nowPaso 2. Obtener el modelo
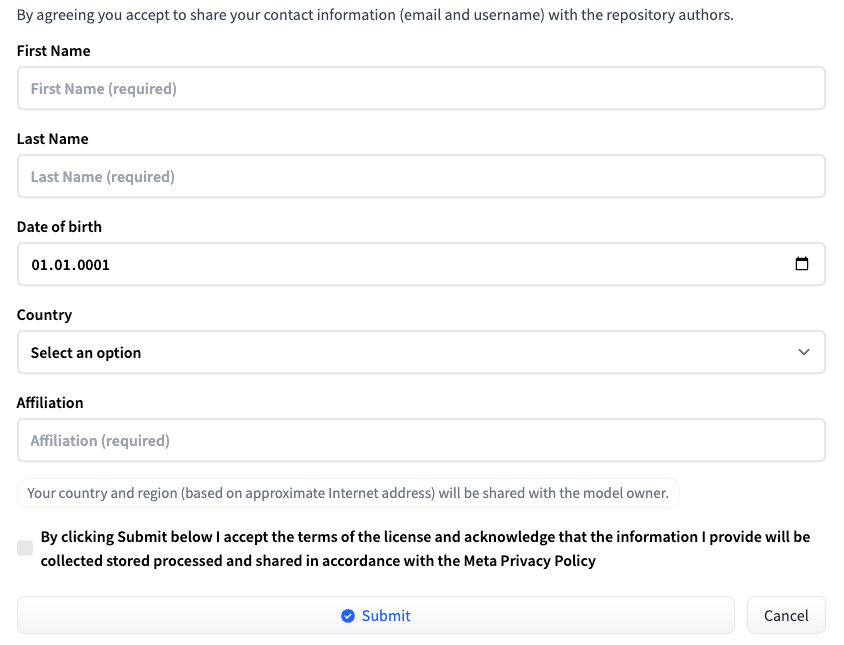
Inicia sesión en Hugging Face con tu nombre de usuario y contraseña. Vaya a la página correspondiente a la versión de LLM deseada: Meta-Llama-3-8B o Meta-Llama-3-70B. En el momento de la publicación de este artículo, el acceso al modelo se proporciona de forma individual. Rellene un breve formulario y haga clic en el botón Submit:
Solicitar acceso a HF
A continuación recibirá un mensaje indicándole que su solicitud ha sido enviada:
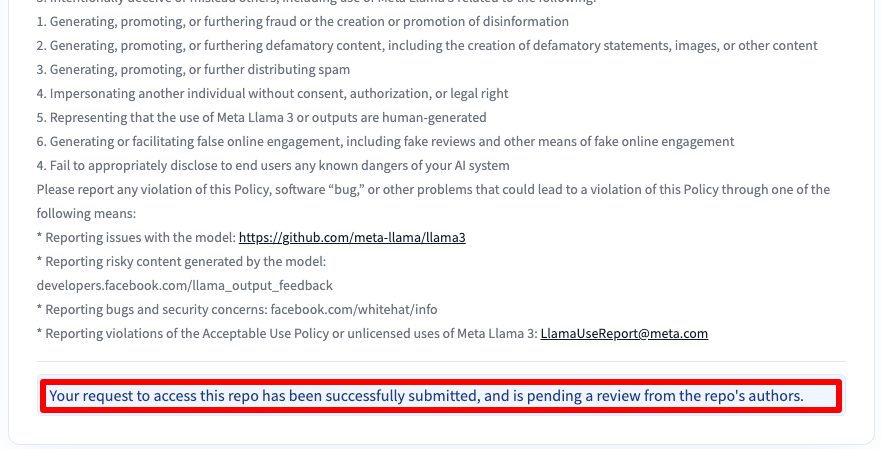
Obtendrá acceso al cabo de 30-40 minutos y se le notificará por correo electrónico.
Añadir clave SSH a HF
Genera y añade una clave SSH que puedas utilizar en Hugging Face:
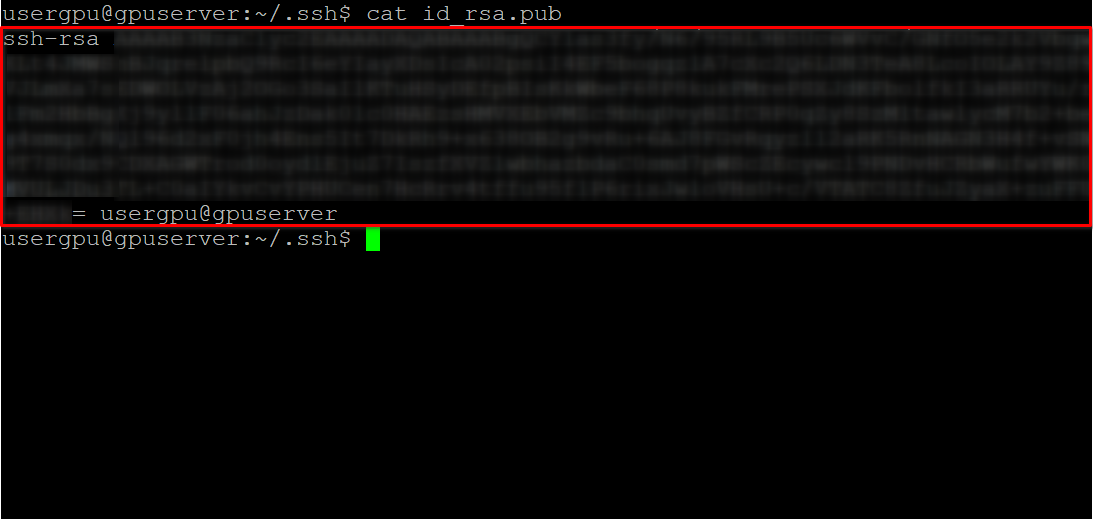
cd ~/.ssh && ssh-keygenCuando se genere el par de claves, podrá visualizar la clave pública en el emulador de terminal:
cat id_rsa.pubCopie toda la información empezando por ssh-rsa y terminando por usergpu@gpuserver como se muestra en la siguiente captura de pantalla:
Abra la configuración del perfil de Hugging Face. A continuación, seleccione SSH and GPG Keys y haga clic en el botón Añadir clave SSH:
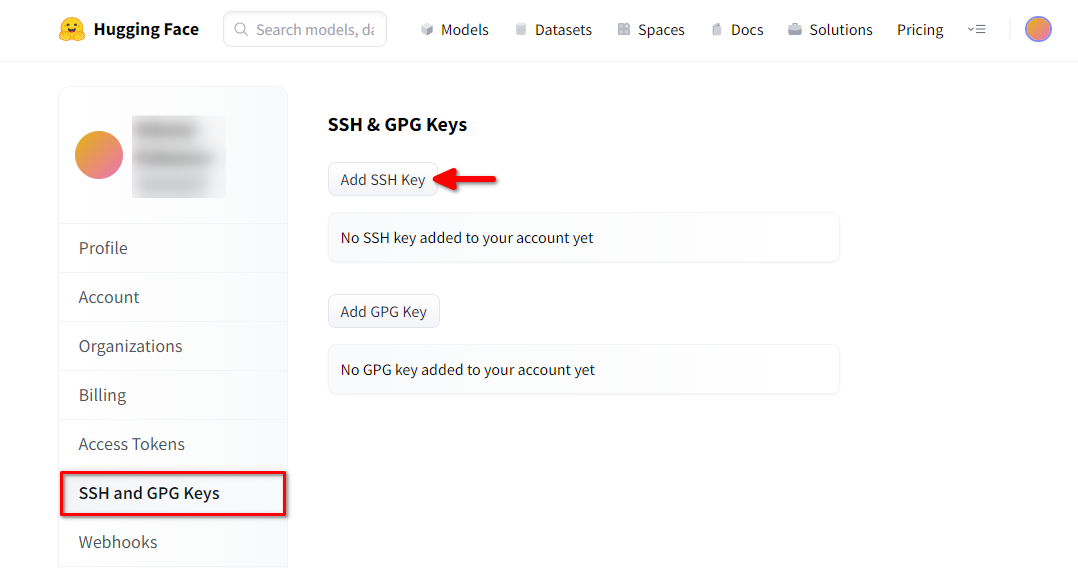
Rellene el Key name y pegue el SSH Public key copiado del terminal. Guarde la clave pulsando Add key:
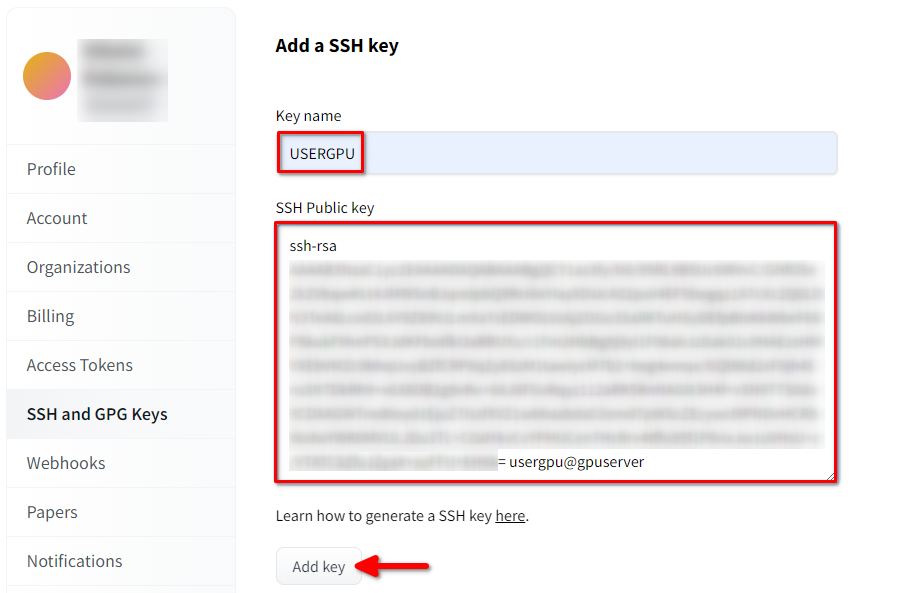
Ahora, tu cuenta HF está vinculada con la clave SSH pública. La segunda parte (clave privada) se almacena en el servidor. El siguiente paso es instalar una extensión específica de Git LFS (Large File Storage), que se utiliza para descargar archivos de gran tamaño, como los modelos de redes neuronales. Abre tu directorio de inicio:
cd ~/Descargue y ejecute el script de shell. Este script instala un nuevo repositorio de terceros con git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashAhora, puedes instalarlo usando el gestor de paquetes estándar:
sudo apt-get install git-lfsVamos a configurar git para utilizar nuestro apodo HF:
git config --global user.name "John"Y vinculado a la cuenta de correo de HF:
git config --global user.email "john.doe@example.com"Descargar el modelo
Abra el directorio de destino:
cd /mnt/fastdiskE inicia la descarga del repositorio. Para este ejemplo elegimos la versión 8B:
git clone git@hf.co:meta-llama/Meta-Llama-3-8BEste proceso tarda hasta 5 minutos. Puede monitorizarlo ejecutando el siguiente comando en otra consola SSH:
watch -n 0.5 df -hAquí verás cómo se reduce el espacio libre en el disco montado, asegurando que la descarga avanza y los datos se guardan. El estado se actualizará cada medio segundo. Para detener manualmente la visualización, pulse la combinación de teclas Ctrl + C.
También puedes instalar btop y supervisar el proceso con esta utilidad:
sudo apt -y install btop && btop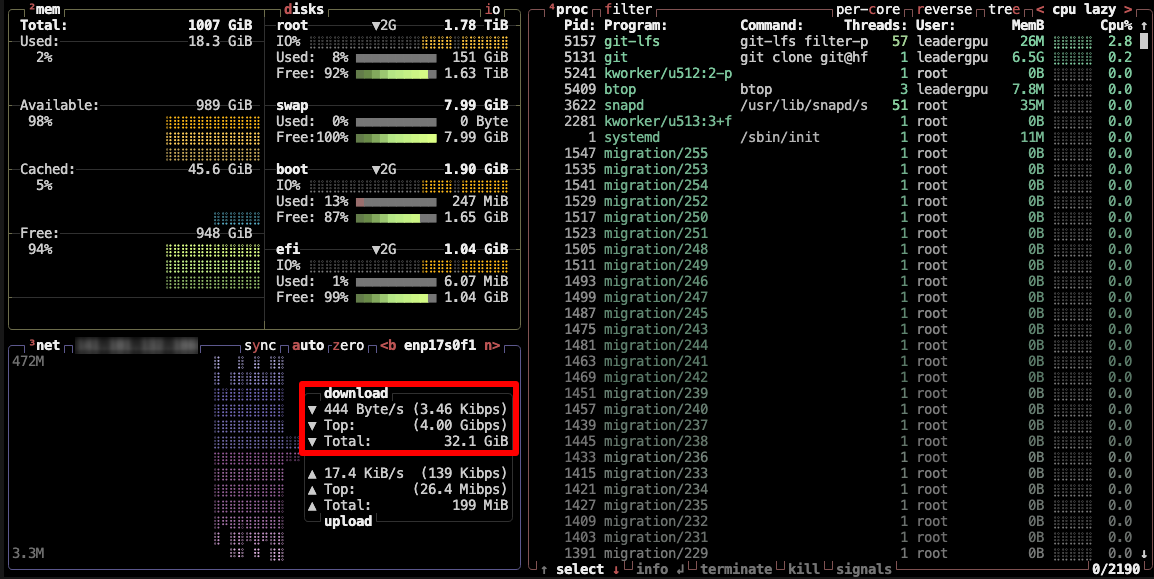
Para salir de la utilidad btop, pulse la tecla Esc y seleccione Quit.
Paso 3. Ejecutar el modelo Ejecutar el modelo
Abra el directorio:
cd /mnt/fastdiskDescarga el repositorio de Llama 3:
git clone https://github.com/meta-llama/llama3Cambia el directorio:
cd llama3Ejecuta el ejemplo:
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir /mnt/fastdisk/Meta-Llama-3-8B/original \
--tokenizer_path /mnt/fastdisk/Meta-Llama-3-8B/original/tokenizer.model \
--max_seq_len 128 \
--max_batch_size 4
Ahora puedes utilizar Llama 3 en tus aplicaciones.
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




