





Tu propia LLaMa 2 en Linux

Paso 1. Preparar el sistema operativo
Actualizar caché y paquetes
Vamos a actualizar la caché de paquetes y actualizar tu sistema operativo antes de empezar a configurar LLaMa 2. Ten en cuenta que para esta guía, estamos utilizando Ubuntu 22.04 LTS como sistema operativo:
sudo apt update && sudo apt -y upgradeAdemás, necesitamos añadir Python Installer Packages (PIP), si no está ya presente en el sistema:
sudo apt install python3-pipInstalar controladores NVIDIA®
Puedes utilizar la utilidad automatizada que se incluye por defecto en las distribuciones de Ubuntu:
sudo ubuntu-drivers autoinstallAlternativamente, puedes instalar los controladores NVIDIA® manualmente usando nuestra guía paso a paso. No olvides reiniciar el servidor:
sudo shutdown -r nowPaso 2. Obtener modelos de MetaAI
Solicitud oficial
Abra la siguiente dirección en su navegador: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Rellene todos los campos necesarios, lea el acuerdo de usuario y haga clic en el botón Agree and Continue. Al cabo de unos minutos (horas, días), recibirá una URL de descarga especial, que le concede permiso para descargar modelos durante un periodo de 24 horas.
Clonar el repositorio
Antes de descargar, comprueba el almacenamiento disponible:
df -hFilesystem Size Used Avail Use% Mounted on tmpfs 38G 3.3M 38G 1% /run /dev/sda2 99G 24G 70G 26% / tmpfs 189G 0 189G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/nvme0n1 1.8T 26G 1.7T 2% /mnt/fastdisk tmpfs 38G 8.0K 38G 1% /run/user/1000
Si tiene discos locales desmontados, por favor siga las instrucciones en Particionado de discos en Linux. Esto es importante porque los modelos descargados pueden ser muy grandes, y es necesario planificar su ubicación de almacenamiento de antemano. En este ejemplo, tenemos un SSD local montado en el directorio /mnt/fastdisk. Vamos a abrirlo:
cd /mnt/fastdiskCrea una copia del repositorio original de LLaMa:
git clone https://github.com/facebookresearch/llamaSi encuentra un error de permiso, simplemente conceda permisos al usuarioergpu:
sudo chown -R usergpu:usergpu /mnt/fastdisk/Descarga mediante script
Abra el directorio descargado:
cd llamaEjecute el script:
./download.shPega la URL proporcionada desde MetaAI y selecciona todos los modelos necesarios. Recomendamos descargar todos los modelos disponibles para evitar solicitar permiso de nuevo. Sin embargo, si necesitas un modelo específico, descarga solo ese.
Prueba rápida a través de una aplicación de ejemplo
Para empezar, podemos comprobar si falta algún componente. Si faltan bibliotecas o aplicaciones, el gestor de paquetes las instalará automáticamente:
pip install -e .El siguiente paso es añadir nuevos binarios al PATH:
export PATH=/home/usergpu/.local/bin:$PATHEjecute el ejemplo de demostración:
torchrun --nproc_per_node 1 /mnt/fastdisk/llama/example_chat_completion.py --ckpt_dir /mnt/fastdisk/llama-2-7b-chat/ --tokenizer_path /mnt/fastdisk/llama/tokenizer.model --max_seq_len 512 --max_batch_size 6La aplicación creará un proceso de cálculo en la primera GPU y simulará un diálogo sencillo con peticiones típicas, generando respuestas utilizando LLaMa 2.
Paso 3. Obtener llama.cpp
LLaMa C++ es un proyecto creado por el físico y desarrollador de software búlgaro Georgi Gerganov. Tiene muchas utilidades que facilitan el trabajo con este modelo de red neuronal. Todas las partes de llama.cpp son software de código abierto y se distribuyen bajo la licencia MIT.
Clonar el repositorio
Abre el directorio de trabajo en el SSD:
cd /mnt/fastdiskClona el repositorio del proyecto:
git clone https://github.com/ggerganov/llama.cpp.gitCompilar aplicaciones
Abre el directorio clonado:
cd llama.cppInicia el proceso de compilación con el siguiente comando:
makePaso 4. Obtener text-generation-webui
Clonar el repositorio
Abra el directorio de trabajo en el SSD:
cd /mnt/fastdiskClona el repositorio del proyecto:
git clone https://github.com/oobabooga/text-generation-webui.gitInstalar requisitos
Abra el directorio descargado:
cd text-generation-webuiCompruebe e instale todos los componentes que faltan:
pip install -r requirements.txtPaso 5. Convertir PTH en GGUF
Formatos comunes
PTH (Python TorcH) - Un formato consolidado. Esencialmente, es un archivo ZIP estándar con un diccionario de estado PyTorch serializado. Sin embargo, este formato tiene alternativas más rápidas como GGML y GGUF.
GGML (Georgi Gerganov’s Machine Learning) - Este es un formato de archivo creado por Georgi Gerganov, el autor de llama.cpp. Se basa en una biblioteca del mismo nombre, escrita en C++, que ha aumentado considerablemente el rendimiento de los modelos lingüísticos de gran tamaño. Ahora ha sido sustituido por el moderno formato GGUF.
GGUF (Georgi Gerganov’s Unified Format) - Se trata de un formato de archivo ampliamente utilizado para los LLM, compatible con diversas aplicaciones. Ofrece mayor flexibilidad, escalabilidad y compatibilidad para la mayoría de los casos de uso.
llama.cpp convert.py script
Edita los parámetros del modelo antes de convertirlo:
nano /mnt/fastdisk/llama-2-7b-chat/params.jsonCorrige "vocab_size": -1 a "vocab_size": 32000. Guarda el archivo y sal. A continuación, abra el directorio llama.cpp:
cd /mnt/fastdisk/llama.cppEjecuta el script que convertirá el modelo al formato GGUF:
python3 convert.py /mnt/fastdisk/llama-2-7b-chat/ --vocab-dir /mnt/fastdisk/llamaSi todos los pasos anteriores son correctos, recibirás un mensaje como este:
Wrote /mnt/fastdisk/llama-2-7b-chat/ggml-model-f16.gguf
Paso 6. WebUI
Cómo iniciar WebUI
Abre el directorio:
cd /mnt/fastdisk/text-generation-webui/Ejecuta el script de inicio con algunos parámetros útiles:
- --model-dir indica la ruta correcta a los modelos
- --share crea un enlace público temporal (si no quieres reenviar un puerto a través de SSH)
- --gradio-auth añade autorización con un nombre de usuario y una contraseña (sustituye usuario:contraseña por los tuyos)
./start_linux.sh --model-dir /mnt/fastdisk/llama-2-7b-chat/ --share --gradio-auth user:passwordTras el lanzamiento con éxito, recibirás un enlace local y un enlace compartido temporal para acceder:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://e9a61c21593a7b251f.gradio.live
Este enlace expira en 72 horas.
Cargar el modelo
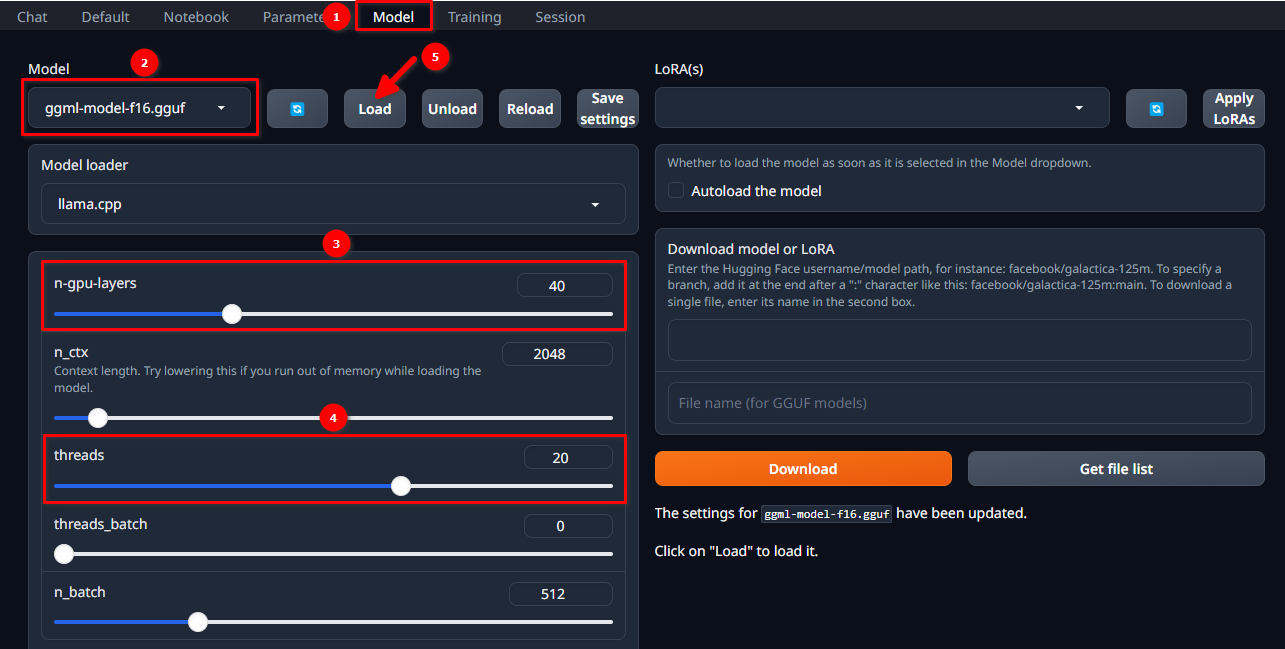
Autorízate en la WebUI utilizando el nombre de usuario y la contraseña seleccionados y sigue estos 5 sencillos pasos:
- Vaya a la pestaña Model.
- Selecciona ggml-model-f16.gguf en el menú desplegable.
- Elige cuántas capas quieres calcular en la GPU (n-gpu-layers).
- Elige cuántos subprocesos quieres iniciar (threads).
- Haz clic en el botón Load.
Inicia el diálogo
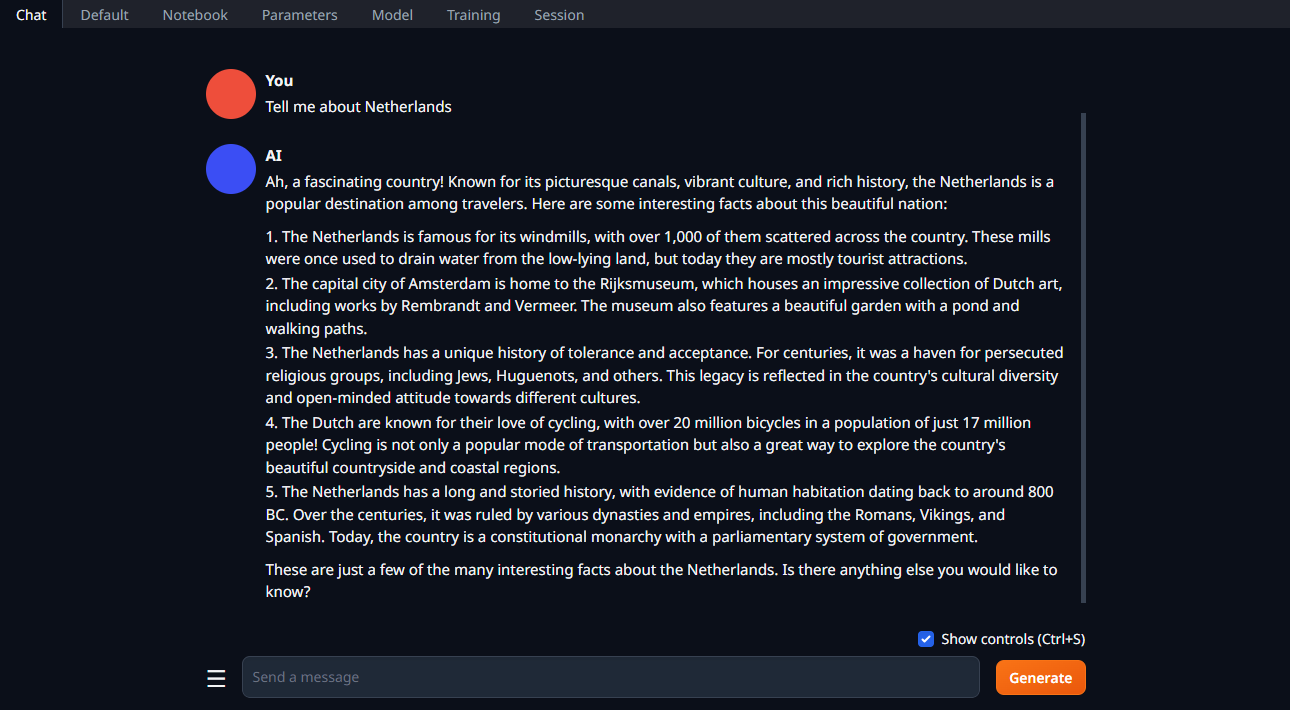
Cambie la pestaña a Chat, escriba su pregunta y haga clic en Generate:
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




