





¿Qué es la destilación de conocimientos?
Los grandes modelos lingüísticos (LLM) se han convertido en parte integrante de nuestras vidas gracias a sus capacidades únicas. Comprenden el contexto y generan textos coherentes y extensos basados en él. Pueden procesar y responder en cualquier idioma teniendo en cuenta los matices culturales de cada uno.
Los LLM destacan en la resolución de problemas complejos, la programación, el mantenimiento de conversaciones y mucho más. Esta versatilidad se debe a que procesan grandes cantidades de datos de entrenamiento, de ahí el término "grandes". Estos modelos pueden contener decenas o cientos de miles de millones de parámetros, lo que hace que consuman muchos recursos para su uso cotidiano.
El entrenamiento es el proceso más exigente. Los modelos de redes neuronales aprenden procesando enormes conjuntos de datos, ajustando sus "pesos" internos para formar conexiones estables entre neuronas. Estas conexiones almacenan conocimientos que la red neuronal entrenada puede utilizar posteriormente en dispositivos finales.
Sin embargo, la mayoría de los dispositivos finales carecen de la potencia de cálculo necesaria para ejecutar estos modelos. Por ejemplo, ejecutar la versión completa de Llama 2 (70B parámetros) requiere una GPU con 48 GB de memoria de vídeo, hardware que pocos usuarios tienen en casa, y menos aún en dispositivos móviles.
En consecuencia, la mayoría de las redes neuronales modernas funcionan en infraestructuras en la nube y no en dispositivos portátiles, que acceden a ellas a través de API. Aun así, los fabricantes de dispositivos están avanzando en dos sentidos: equipando los dispositivos con unidades de cálculo especializadas, como las NPU, y desarrollando métodos para mejorar el rendimiento de los modelos compactos de redes neuronales.
Reducir el tamaño
Cortar el exceso
La cuantización es el primer método, y el más eficaz, para reducir el tamaño de una red neuronal. Los pesos de las redes neuronales suelen utilizar números de 32 bits en coma flotante, pero podemos reducirlos cambiando este formato. Utilizar valores de 8 bits (o incluso unos binarios en algunos casos) puede reducir diez veces el tamaño de la red, aunque esto disminuye significativamente la precisión de la respuesta.
La poda es otro método que elimina las conexiones sin importancia de la red neuronal. Este proceso funciona tanto durante el entrenamiento como con las redes terminadas. Además de las conexiones, la poda puede eliminar neuronas o capas enteras. Esta reducción de parámetros y conexiones reduce los requisitos de memoria.
La descomposición matricial o tensorial es la tercera técnica habitual de reducción de tamaño. La descomposición de una matriz grande en un producto de tres matrices más pequeñas reduce los parámetros totales manteniendo la calidad. Esto puede reducir el tamaño de la red decenas de veces. La descomposición tensorial ofrece resultados aún mejores, aunque requiere más hiperparámetros.
Aunque estos métodos reducen eficazmente el tamaño, todos se enfrentan al reto de la pérdida de calidad. Los modelos comprimidos de gran tamaño superan a sus homólogos más pequeños sin comprimir, pero cada compresión corre el riesgo de reducir la precisión de la respuesta. La destilación del conocimiento representa un intento interesante de equilibrar la calidad con el tamaño.
Intentémoslo juntos
La destilación de conocimientos se explica mejor mediante la analogía de un alumno y un profesor. Mientras los alumnos aprenden, los profesores enseñan y también actualizan continuamente sus conocimientos. Cuando ambos se encuentran con nuevos conocimientos, el profesor tiene ventaja, puede recurrir a sus amplios conocimientos de otras áreas, mientras que el alumno carece aún de esta base.
Este principio se aplica a las redes neuronales. Cuando se entrenan dos redes neuronales del mismo tipo pero de distinto tamaño con datos idénticos, la red más grande suele obtener mejores resultados. Su mayor capacidad de "conocimiento" permite respuestas más precisas que su homóloga más pequeña. Esto plantea una posibilidad interesante: ¿por qué no entrenar la red más pequeña no sólo con el conjunto de datos, sino también con los resultados más precisos de la red más grande?
Este proceso es la destilación del conocimiento: una forma de aprendizaje supervisado en el que un modelo más pequeño aprende a replicar las predicciones de uno más grande. Aunque esta técnica ayuda a compensar la pérdida de calidad al reducir el tamaño de la red neuronal, requiere más recursos informáticos y tiempo de entrenamiento.
Software y lógica
Una vez aclarados los fundamentos teóricos, examinemos el proceso desde una perspectiva técnica. Empezaremos con las herramientas de software que pueden guiarle a través de las etapas de formación y destilación de conocimientos.
Python, junto con la biblioteca TorchTune del ecosistema PyTorch, ofrece el enfoque más sencillo para estudiar y afinar grandes modelos lingüísticos. He aquí cómo funciona la aplicación:
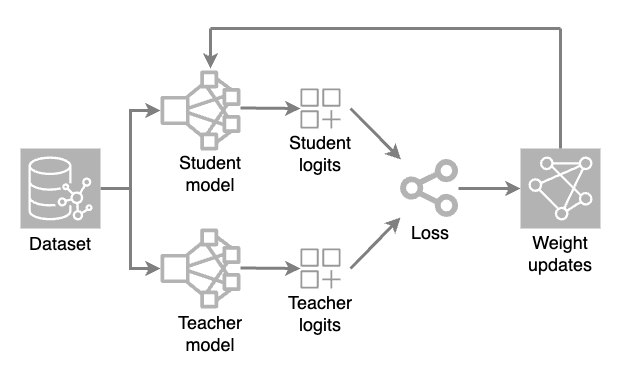
Se cargan dos modelos: un modelo completo (profesor) y un modelo reducido (alumno). Durante cada iteración de entrenamiento, el modelo del profesor genera predicciones de alta temperatura, mientras que el modelo del alumno procesa el conjunto de datos para hacer sus propias predicciones.
Los valores de salida brutos (logits) de ambos modelos se evalúan mediante una función de pérdida (una medida numérica de cuánto se desvía una predicción del valor correcto). A continuación, se aplican ajustes de peso al modelo del alumno mediante retropropagación. Esto permite al modelo más pequeño aprender y replicar las predicciones del modelo maestro.
El principal archivo de configuración del código de la aplicación se denomina receta. Este archivo almacena todos los parámetros y ajustes de destilación, lo que hace que los experimentos sean reproducibles y permite a los investigadores hacer un seguimiento de cómo influyen los distintos parámetros en el resultado final.
A la hora de seleccionar los valores de los parámetros y el número de iteraciones, es fundamental mantener el equilibrio. Un modelo que se destila demasiado puede perder su capacidad de reconocer detalles sutiles y el contexto, recurriendo por defecto a respuestas planificadas. Aunque el equilibrio perfecto es casi imposible de conseguir, una supervisión cuidadosa del proceso de destilación puede mejorar sustancialmente la calidad de la predicción incluso de los modelos de redes neuronales más modestos.
También merece la pena prestar atención a la supervisión durante el proceso de entrenamiento. Esto ayudará a identificar los problemas a tiempo y a corregirlos con prontitud. Para ello, puede utilizar la herramienta TensorBoard. Se integra perfectamente en los proyectos PyTorch y permite evaluar visualmente muchas métricas, como la precisión y las pérdidas. Además, permite construir un gráfico del modelo, hacer un seguimiento del uso de memoria y del tiempo de ejecución de las operaciones.
Conclusión
La destilación del conocimiento es un método eficaz para optimizar las redes neuronales con el fin de mejorar los modelos compactos. Funciona mejor cuando es esencial equilibrar el rendimiento con la calidad de la respuesta.
Aunque la destilación de conocimientos requiere un seguimiento cuidadoso, sus resultados pueden ser notables. Los modelos se hacen mucho más pequeños manteniendo la calidad de la predicción, y funcionan mejor con menos recursos informáticos.
Cuando se planifica bien con los parámetros adecuados, la destilación de conocimientos sirve como herramienta clave para crear redes neuronales compactas sin sacrificar la calidad.
Ver también:
Actualizado: 04.01.2026
Publicado: 23.01.2025




