





Qwen3-Coder: un paradigma roto

Estamos acostumbrados a pensar que los modelos de código abierto siempre están por detrás de sus homólogos comerciales en cuanto a calidad. Puede parecer que están desarrollados exclusivamente por entusiastas que no pueden permitirse invertir grandes sumas en crear conjuntos de datos de alta calidad y entrenar modelos en decenas de miles de GPU modernas.
La cosa cambia cuando grandes corporaciones como OpenAI, Anthropic o Meta asumen la tarea. No sólo disponen de los recursos necesarios, sino también de los mejores especialistas en redes neuronales del mundo. Por desgracia, los modelos que crean, especialmente las últimas versiones, son de código cerrado. Los desarrolladores lo explican alegando los riesgos de un uso incontrolado y la necesidad de garantizar la seguridad de la IA.
Por un lado, su razonamiento es comprensible: muchas cuestiones éticas siguen sin resolverse y la propia naturaleza de los modelos de redes neuronales sólo permite influir indirectamente en el resultado final. Por otro lado, mantener los modelos cerrados y ofrecer acceso sólo a través de su propia API es también un modelo de negocio sólido.
Sin embargo, no todas las empresas se comportan así. Por ejemplo, la empresa francesa Mistral AI ofrece modelos comerciales y de código abierto, lo que permite a investigadores y aficionados utilizarlos en sus proyectos. Pero hay que prestar especial atención a los logros de las empresas chinas, la mayoría de las cuales construyen modelos de peso y código abiertos capaces de competir seriamente con las soluciones propietarias.
DeepSeek, Qwen3 y Kimi K2
El primer gran avance llegó con DeepSeek-V3. Este modelo lingüístico multimodal de DeepSeek AI se desarrolló utilizando el enfoque de Mezcla de Expertos (MoE) y unos impresionantes 671B parámetros, con 37B de los más relevantes activados para cada token. Y lo que es más importante, todos sus componentes (pesos del modelo, código de inferencia y conductos de formación) se han hecho públicos.
Esto lo convirtió instantáneamente en uno de los LLM más atractivos para desarrolladores de aplicaciones de IA e investigadores por igual. El siguiente titular fue DeepSeek-R1, el primer modelo de razonamiento de código abierto. El día de su lanzamiento, hizo temblar el mercado bursátil estadounidense después de que sus desarrolladores afirmaran que entrenar un modelo tan avanzado sólo había costado 6 millones de dólares.
Aunque el revuelo en torno a DeepSeek acabó por enfriarse, los siguientes lanzamientos no fueron menos importantes para la industria mundial de la IA. Hablamos, por supuesto, de Qwen 3. En nuestro análisis de Novedades de Qwen 3 tratamos en detalle sus características, por lo que no nos detendremos en él. Poco después apareció otro jugador: Kimi K2, de Moonshot AI.
Con su arquitectura MoE, parámetros 1T (32B activados por token) y código abierto, Kimi K2 atrajo rápidamente la atención de la comunidad. En lugar de centrarse en el razonamiento, Moonshot AI buscaba un rendimiento puntero en matemáticas, programación y conocimientos transversales profundos.
El as en la manga de Kimi K2 era su optimización para la integración en agentes de IA. Esta red se diseñó literalmente para aprovechar al máximo todas las herramientas disponibles. Sobresale en tareas que requieren no sólo escribir código, sino también pruebas iterativas en cada fase de desarrollo. Sin embargo, también tiene puntos débiles, que discutiremos más adelante.
Kimi K2 es un modelo de lenguaje grande en todos los sentidos. Ejecutar la versión completa requiere ~2 TB de VRAM (FP8: ~1 TB). Por razones obvias, esto no es algo que puedas hacer en casa, e incluso muchos servidores de GPU no lo soportarán. El modelo necesita al menos 8 aceleradores NVIDIA® H200. Las versiones cuantificadas pueden ayudar, pero con un coste notable para la precisión.
Codificador Qwen3
Viendo el éxito de Moonshot AI, Alibaba desarrolló su propio modelo similar a Kimi K2, pero con importantes ventajas que comentaremos en breve. Inicialmente, se lanzó en dos versiones:
- Qwen3-Coder-480B-A35B-Instruct (~250 GB VRAM)
- Qwen3-Coder-480B-A35B-Instruct-FP8 (~120 GB de VRAM)
Pocos días después, aparecieron modelos más pequeños sin el mecanismo de razonamiento, que requerían mucha menos VRAM:
- Qwen3-Coder-30B-A3B-Instruct (~32 GB VRAM)
- Qwen3-Coder-30B-A3B-Instruct-FP8 (~18 GB VRAM)
Qwen3-Coder fue diseñado para su integración con herramientas de desarrollo. Incluye un analizador especial para llamadas a funciones (qwen3coder_tool_parser.py, análogo a la llamada a funciones de OpenAI). Junto con el modelo, se ha lanzado una utilidad de consola, capaz de realizar desde la compilación de código hasta la consulta de una base de conocimientos. Esta idea no es nueva, esencialmente es una extensión muy reelaborada de la aplicación de código Gemini de Anthropic.
El modelo es compatible con la API OpenAI, lo que permite desplegarlo localmente o en un servidor remoto y conectarlo a la mayoría de los sistemas que admiten esta API. Esto incluye tanto aplicaciones cliente ya creadas como bibliotecas de aprendizaje automático. Esto lo hace viable no sólo para el segmento B2C, sino también para el B2B, ofreciendo un reemplazo drop-in sin fisuras para el producto de OpenAI sin ningún cambio en la lógica de la aplicación.
Una de sus características más demandadas es la longitud de contexto ampliada. Por defecto, admite 256k tokens, pero puede aumentarse hasta 1M utilizando el mecanismo YaRN (Yet another RoPe extensioN). Los LLM modernos se entrenan normalmente con conjuntos de datos cortos (2.000-8.000 tokens), y una longitud de contexto grande puede hacer que pierdan de vista el contenido anterior.
YaRN es un elegante "truco" que hace creer al modelo que está trabajando con sus secuencias cortas habituales, mientras que en realidad procesa secuencias mucho más largas. La idea clave es "estirar" o "dilatar" el espacio posicional conservando la estructura matemática que espera el modelo. Esto permite procesar eficazmente secuencias de decenas de miles de tokens sin el reentrenamiento o la memoria adicional que exigen los métodos tradicionales de ampliación del contexto.
Descarga y ejecución de Inference
Asegúrate de haber instalado CUDA® de antemano, ya sea utilizando las instrucciones oficiales de NVIDIA® o la guía Instalar el kit de herramientas CUDA® en Linux. Para comprobar el compilador necesario:
nvcc --versionSalida esperada:
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0
Si obtiene:
Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit
necesitas añadir los binarios CUDA® al $PATH de tu sistema.
export PATH=/usr/local/cuda-12.4/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATHEsta es una solución temporal. Para una solución permanente, edite ~/.bashrc y añada las mismas dos líneas al final.
Ahora, prepara tu sistema para gestionar entornos virtuales. Puedes usar el venv incorporado en Python o el más avanzado Miniforge. Asumiendo que Miniforge está instalado:
conda create -n venv python=3.10conda activate venvInstala PyTorch con soporte CUDA® compatible con tu sistema:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124A continuación, instale las bibliotecas esenciales:
- Transformers - La biblioteca de modelos principal de Hugging Face
- Accelerate - permite la inferencia multi-GPU
- HuggingFace Hub - para descargar/cargar modelos y conjuntos de datos
- Safetensors - formato seguro del peso del modelo
- vLLM - biblioteca de inferencia recomendada para Qwen
pip install transformers accelerate huggingface_hub safetensors vllmDescargar el modelo:
hf download Qwen/Qwen3-Coder-30B-A3B-Instruct --local-dir ./Qwen3-30BEjecutar la inferencia con paralelismo tensorial (repartiendo los tensores de capa entre las GPUs, por ejemplo 8):
python -m vllm.entrypoints.openai.api_server \
--model /home/usergpu/Qwen3-30B \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--dtype auto \
--host 0.0.0.0 \
--port 8000Esto inicia el servidor API OpenAI de vLLM.
Pruebas e integración
cURL
Instale jq para la impresión bonita de JSON:
sudo apt -y install jqProbar el servidor:
curl -s http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/usergpu/Qwen3-30B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! What can you do?"}
],
"max_tokens": 180
}' | jq -r '.choices[0].message.content'VSCode
Para integrarse con Visual Studio Code, instale la extensión Continue y añádala a config.yaml:
- name: Qwen3-Coder 30B
provider: openai
apiBase: http://[server_IP_address]:8000/v1
apiKey: none
model: /home/usergpu/Qwen3-30B
roles:
- chat
- edit
- apply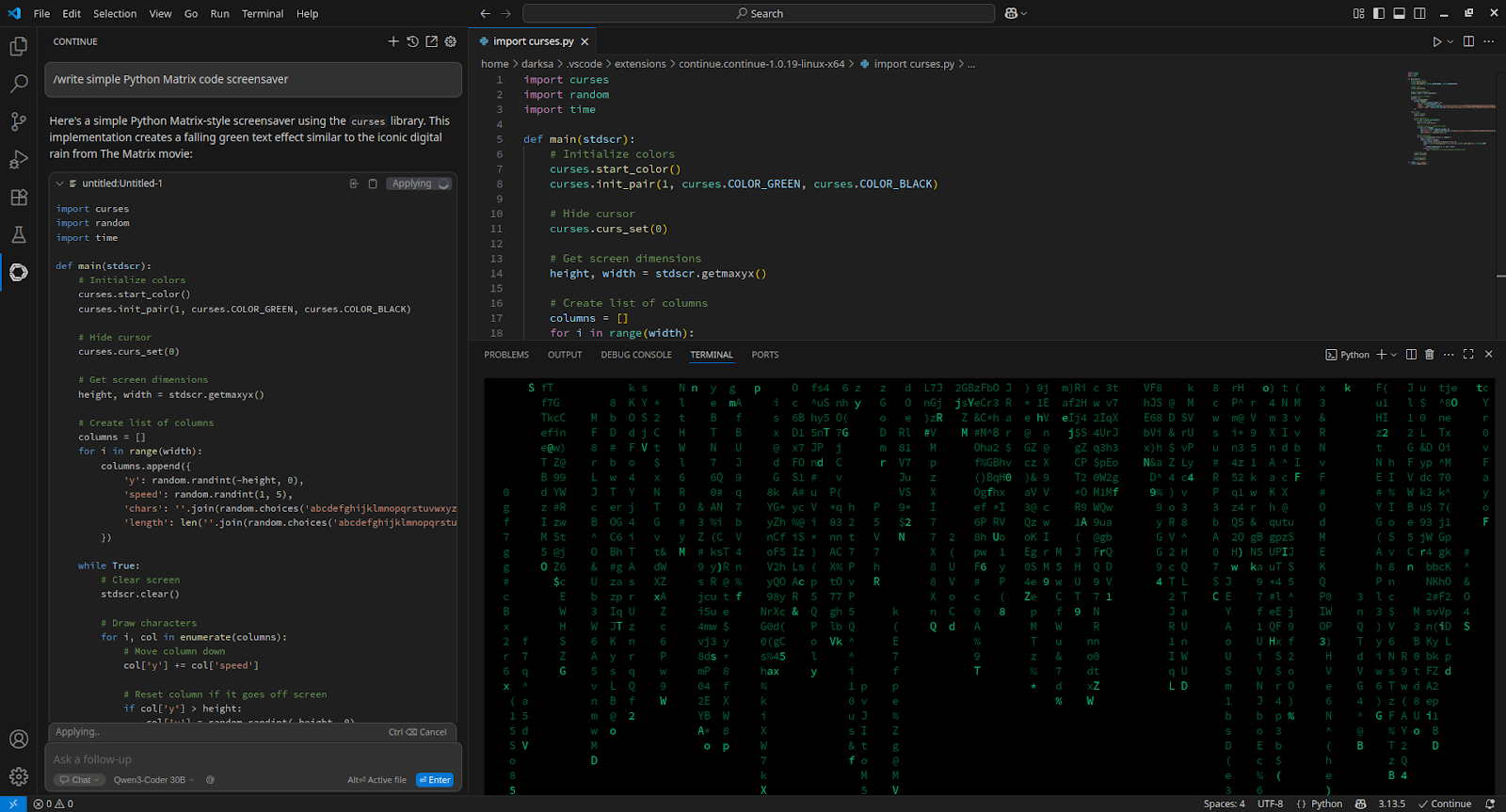
Qwen-Agente
Para una configuración basada en GUI con Qwen-Agent (incluyendo RAG, MCP e intérprete de código):
pip install -U "qwen-agent[gui,rag,code_interpreter,mcp]"Abre el editor nano:
nano script.pyEjemplo de script Python para lanzar Qwen-Agent con Gradio WebUI:
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
llm_cfg = {
'model': '/home/usergpu/Qwen3-30B',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
'generate_cfg': {'top_p': 0.8},
}
tools = ['code_interpreter']
bot = Assistant(
llm=llm_cfg,
system_message="You are a helpful coding assistant.",
function_list=tools
)
WebUI(bot).run()Ejecute el script:
python script.pyEl servidor estará disponible en: http://127.0.0.1:7860
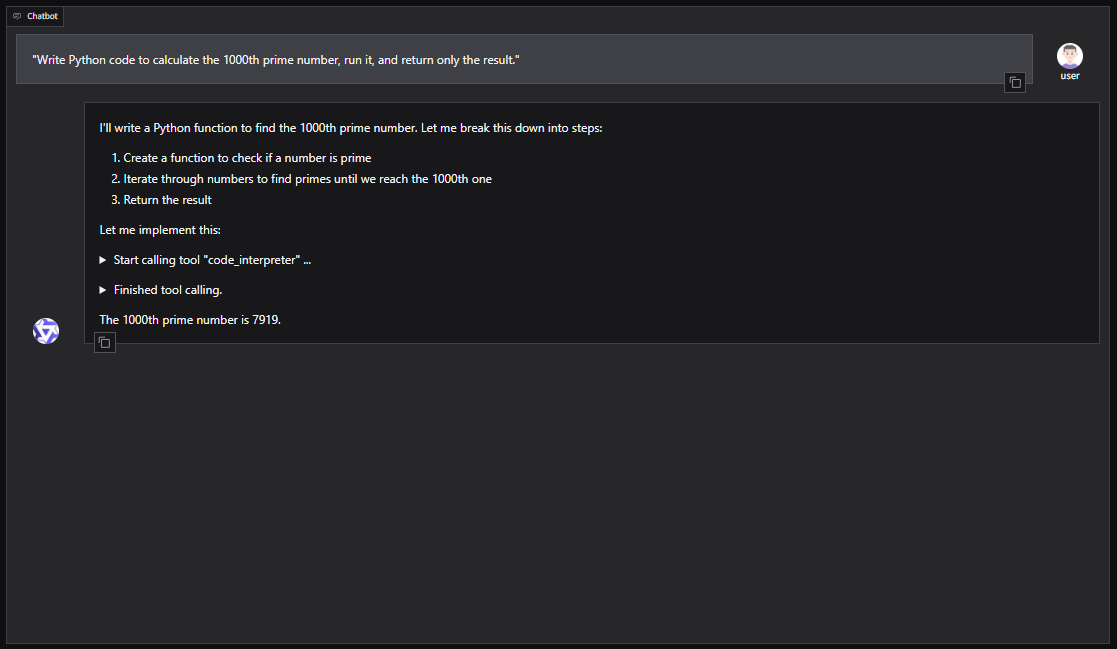
También puedes integrar Qwen3-Coder en frameworks de agentes como CrewAI para automatizar tareas complejas con conjuntos de herramientas como la búsqueda web o la memoria de bases de datos vectoriales.
Véase también:
Actualizado: 04.01.2026
Publicado: 12.08.2025




