





Qwen 2 vs Llama 3

Los grandes modelos lingüísticos (LLM) han tenido un gran impacto en nuestras vidas. A pesar de comprender su estructura interna, estos modelos siguen siendo un foco de atención para los científicos, que a menudo los comparan con una "caja negra". El resultado final depende no sólo del diseño del LLM, sino también de su entrenamiento y de los datos utilizados para éste.
Mientras que los científicos encuentran oportunidades de investigación, a los usuarios finales les interesan sobre todo dos cosas: la velocidad y la calidad. Estos criterios desempeñan un papel crucial en el proceso de selección. Para comparar con precisión dos LLM, es necesario estandarizar muchos factores aparentemente no relacionados.
El equipo utilizado para las interferencias y el entorno de software, incluidos el sistema operativo, las versiones de los controladores y los paquetes de software, son los que más influyen. Es esencial seleccionar una versión de LLM que funcione en varios equipos y elegir una métrica de velocidad que sea fácilmente comprensible.
Como métrica hemos seleccionado "tokens por segundo" (tokens/s). Es importante tener en cuenta que un token ≠ una palabra. El LLM descompone las palabras en componentes más simples, típicos de un idioma concreto, denominados tokens.
La predictibilidad estadística del siguiente carácter varía de un idioma a otro, por lo que la tokenización será diferente. Por ejemplo, en inglés, de cada 75 palabras se obtienen aproximadamente 100 tokens. En las lenguas que utilizan el alfabeto cirílico, el número de fichas por palabra puede ser mayor. Así, 75 palabras en una lengua cirílica, como el ruso, podrían equivaler a 120-150 tokens.
Puedes comprobarlo con la herramienta Tokenizer de OpenAI. Muestra en cuántos tokens se divide un fragmento de texto, lo que convierte a los 'tokens por segundo' en un buen indicador de la velocidad y el rendimiento del procesamiento del lenguaje natural de un LLM.
Cada prueba se realizó en el sistema operativo Ubuntu 22.04 LTS con los controladores de NVIDIA® versión 535.183.01 y el kit de herramientas NVIDIA® CUDA® 12.5 instalados. Se formularon preguntas para evaluar la calidad y velocidad del LLM. La velocidad de procesamiento de cada respuesta se registró y contribuirá al valor medio de cada configuración probada.
Comenzamos probando varias GPU, desde los modelos más recientes hasta los más antiguos. Una condición crucial para la prueba era que midiéramos el rendimiento de una sola GPU, aunque hubiera varias en la configuración del servidor. Esto se debe a que el rendimiento de una configuración con varias GPU depende de factores adicionales como la presencia de una interconexión de alta velocidad entre ellas (NVLink).
Además de la velocidad, también intentamos evaluar la calidad de las respuestas en una escala de 5 puntos, donde 5 representa el mejor resultado. Esta información se facilita aquí únicamente para una comprensión general. Cada vez, plantearemos las mismas preguntas a la red neuronal e intentaremos discernir con qué precisión comprende cada una lo que el usuario quiere de ella.
Qwen 2
Recientemente, un equipo de desarrolladores de Alibaba Group presentó la segunda versión de su red neuronal generativa Qwen. Entiende 27 idiomas y está bien optimizada para ellos. Qwen 2 se presenta en distintos tamaños para facilitar su implantación en cualquier dispositivo (desde sistemas embebidos con recursos muy limitados hasta un servidor dedicado con GPU):
- 0,5B: adecuado para IoT y sistemas embebidos;
- 1,5B: versión ampliada para sistemas embebidos, utilizada cuando las capacidades de 0,5B no son suficientes;
- 7B: modelo de tamaño medio, muy adecuado para el procesamiento del lenguaje natural;
- 57B: modelo grande de alto rendimiento, adecuado para aplicaciones exigentes;
- 72B: el modelo Qwen 2 definitivo, diseñado para resolver los problemas más complejos y procesar grandes volúmenes de datos.
Las versiones 0.5B y 1.5B se entrenaron en conjuntos de datos con una longitud de contexto de 32K. Las versiones 7B y 72B se entrenaron ya con el contexto de 128K. El modelo de compromiso 57B se entrenó en conjuntos de datos con una longitud de contexto de 64K. Los creadores posicionan Qwen 2 como un análogo de Llama 3 capaz de resolver los mismos problemas, pero mucho más rápido.
Llama 3
La tercera versión de la red neuronal generativa de la familia MetaAI Llama se presentó en abril de 2024. Fue lanzada, a diferencia de Qwen 2, sólo en dos versiones: 8B y 70B. Estos modelos se posicionaron como una herramienta universal para resolver muchos problemas en diversos casos. Continuaba la tendencia hacia el multilingüismo y la multimodalidad, al tiempo que se hacía más rápida que las versiones anteriores y admitía una mayor longitud de contexto.
Los creadores de Llama 3 intentaron afinar los modelos para reducir el porcentaje de alucinaciones estadísticas y aumentar la variedad de respuestas. Así, Llama 3 es muy capaz de dar consejos prácticos, ayudar a redactar una carta comercial o especular sobre un tema especificado por el usuario. Los conjuntos de datos en los que se entrenaron los modelos de Llama 3 tenían una longitud de contexto de 128K y más del 5% incluían datos en 30 idiomas. Sin embargo, como se afirma en el comunicado de prensa, el rendimiento de la generación en inglés será significativamente mayor que en cualquier otro idioma.
Comparación
NVIDIA® RTX™ A6000
Empecemos nuestras mediciones de velocidad con la GPU NVIDIA® RTX™ A6000, basada en la arquitectura Ampere (no confundir con la NVIDIA® RTX™ A6000 Ada). Esta tarjeta tiene unas características muy modestas, pero al mismo tiempo dispone de 48 GB de VRAM, lo que le permite funcionar con modelos de redes neuronales bastante grandes. Por desgracia, la baja velocidad de reloj y el escaso ancho de banda son las razones de la baja velocidad de inferencia de los LLM de texto.
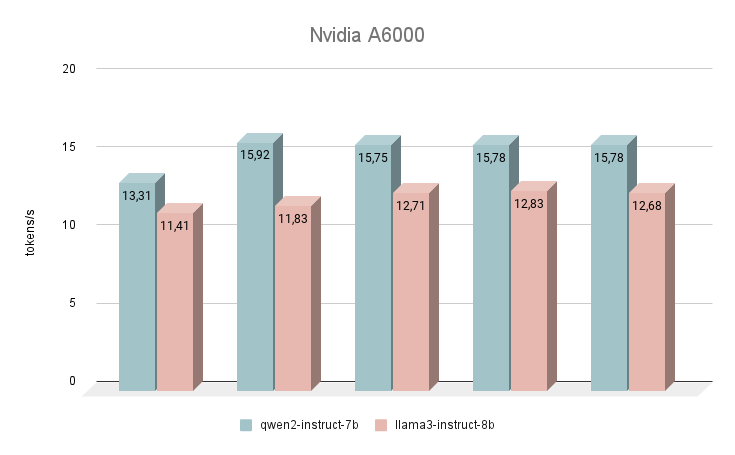
Inmediatamente después de su lanzamiento, la red neuronal Qwen 2 empezó a superar a Llama 3. Al responder a las mismas preguntas, la diferencia media de velocidad fue del 24% a favor de Qwen 2. La velocidad de generación de respuestas se situó en el rango de 11-16 tokens por segundo. Esto es 2-3 veces más rápido que intentar ejecutar la generación incluso en una CPU potente, pero en nuestra clasificación, este es el resultado más modesto.
NVIDIA® RTX™ 3090
La siguiente GPU también se basa en la arquitectura Ampere, tiene 2 veces menos memoria de vídeo, pero al mismo tiempo, funciona a una frecuencia más alta (19500 MHz frente a 16000 Mhz). El ancho de banda de la memoria de vídeo también es mayor (936,2 GB/s frente a 768 GB/s). Ambos factores aumentan considerablemente el rendimiento de la RTX™ 3090, incluso teniendo en cuenta que tiene 256 núcleos CUDA® menos.
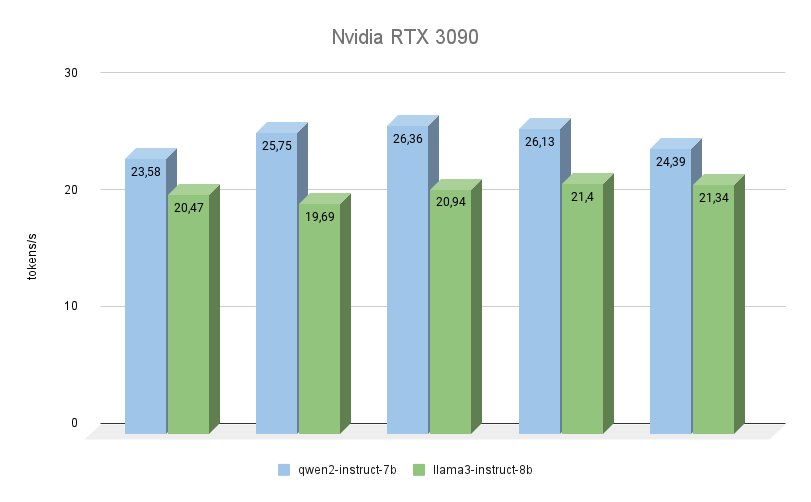
Aquí se ve claramente que Qwen 2 es mucho más rápida (hasta un 23%) que Llama 3 al realizar las mismas tareas. En cuanto a la calidad de la generación, el soporte multilingüe de Qwen 3 es realmente digno de elogio, y el modelo siempre responde en el mismo idioma en el que se formuló la pregunta. Con Llama 3, en este sentido, ocurre a menudo que el modelo entiende la pregunta en sí, pero prefiere formular las respuestas en inglés.
NVIDIA® RTX™ 4090
Ahora lo más interesante: veamos cómo la NVIDIA® RTX™ 4090, construida sobre la arquitectura Ada Lovelace, llamada así por la matemática inglesa Augusta Ada King, condesa de Lovelace, se enfrenta a la misma tarea. Se hizo famosa por ser la primera programadora de la historia de la humanidad, y en el momento de escribir su primer programa no existía ningún ordenador ensamblado que pudiera ejecutarlo. Sin embargo, se reconoció que el algoritmo descrito por Ada para calcular los números de Bernoulli fue el primer programa del mundo escrito para ser ejecutado en un ordenador.
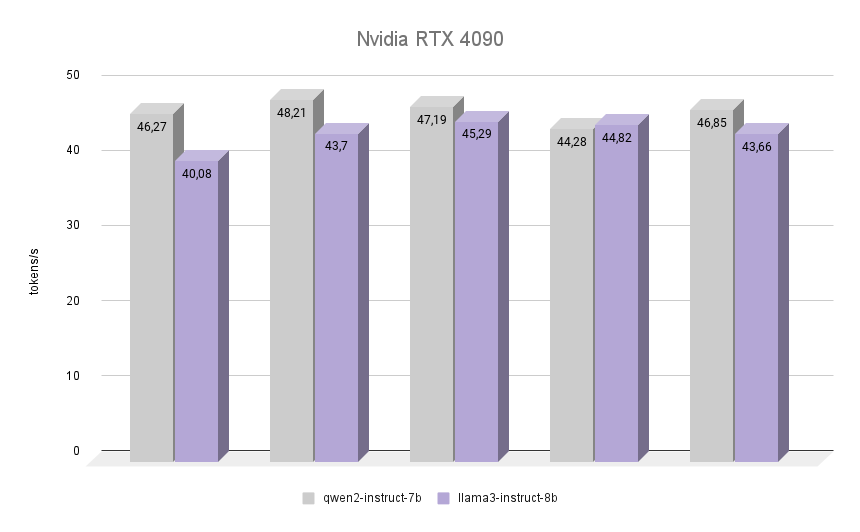
El gráfico muestra claramente que la RTX™ 4090 hizo frente a la inferencia de ambos modelos casi el doble de rápido. Es interesante que en una de las iteraciones Llama 3 consiguiera superar a Qwen 2 en un 1,2%. Sin embargo, teniendo en cuenta las demás iteraciones, Qwen 2 mantuvo su liderazgo, siendo un 7% más rápido que Llama 3. En todas las iteraciones, la calidad de las respuestas de ambas redes neuronales fue alta, con un número mínimo de alucinaciones. El único defecto es que en contadas ocasiones se mezclaron uno o dos caracteres chinos en las respuestas, lo que no afectó en absoluto al significado global.
NVIDIA® RTX™ A40
La siguiente tarjeta NVIDIA® RTX™ A40, con la que realizamos pruebas similares, se basa de nuevo en la arquitectura Ampere y cuenta con 48 GB de memoria de vídeo en la placa base. Comparada con la RTX™ 3090, esta memoria es ligeramente más rápida (20000 MHz frente a 19500 MHz), pero tiene menor ancho de banda (695,8 GB/s frente a 936,2 GB/s). La situación se compensa con el mayor número de núcleos CUDA® (10752 frente a 10496), lo que en conjunto permite a la RTX™ A40 rendir ligeramente más rápido que la RTX™ 3090.
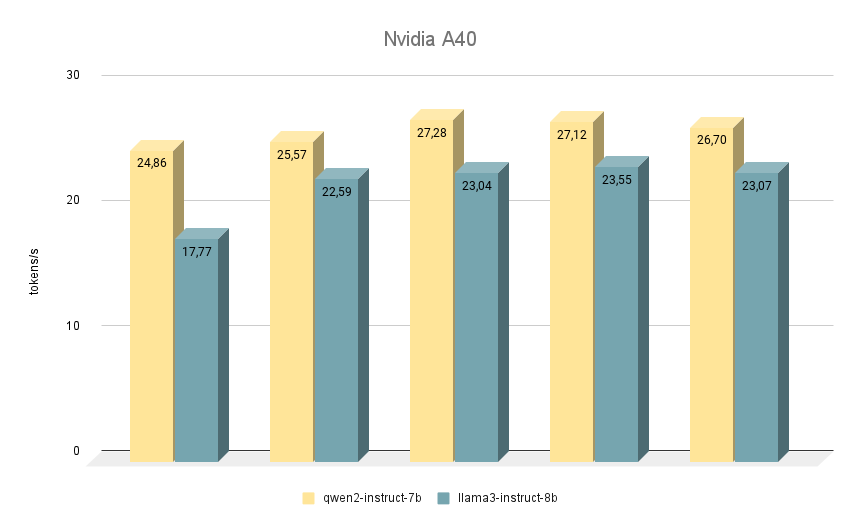
En cuanto a la comparación de la velocidad de los modelos, aquí Qwen 2 también está por delante de Llama 3 en todas las iteraciones. Cuando se ejecuta en RTX™ A40, la diferencia de velocidad es de aproximadamente un 15% con las mismas respuestas. En algunas tareas, Qwen 2 dio un poco más de información importante, mientras que Llama 3 fue lo más específico posible y dio ejemplos. A pesar de ello, hay que comprobarlo todo dos veces, ya que a veces ambos modelos empiezan a dar respuestas controvertidas.
NVIDIA® L20
La última participante en nuestras pruebas fue la NVIDIA® L20. Esta GPU está construida como la RTX™ 4090, sobre la arquitectura Ada Lovelace. Se trata de un modelo bastante nuevo, presentado en otoño de 2023. A bordo, tiene 48 GB de memoria de vídeo y 11776 núcleos CUDA®. El ancho de banda de memoria es inferior al de la RTX™ 4090 (864 GB/s frente a 936,2 GB/s), al igual que la frecuencia efectiva. Por tanto, las puntuaciones de inferencia NVIDIA® L20 de ambos modelos estarán más cerca de la 3090 que de la 4090.
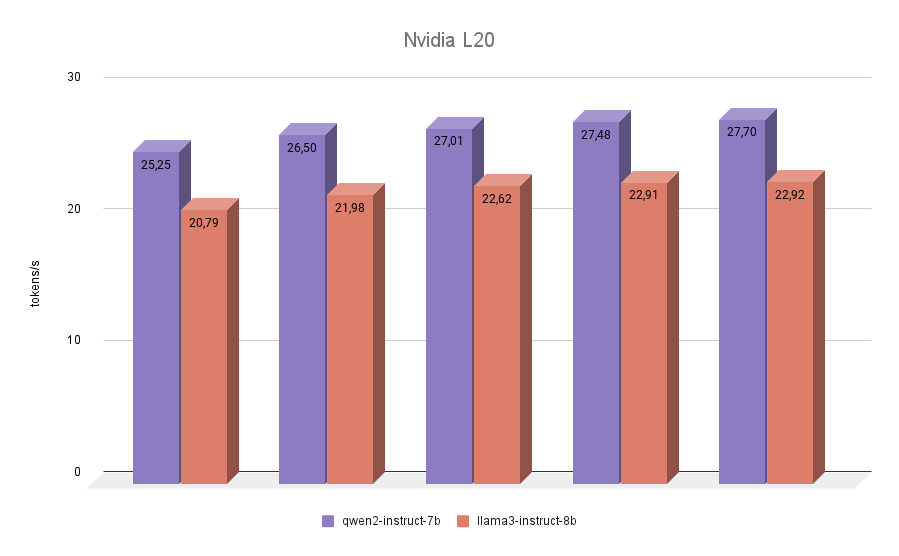
La prueba final no trajo sorpresas. Qwen 2 resultó ser más rápido que Llama 3 en todas las iteraciones.
Conclusión
Combinemos todos los resultados recogidos en un gráfico. Qwen 2 fue entre un 7% y un 24% más rápido que Llama 3 dependiendo de la GPU utilizada. Basándonos en esto, podemos concluir claramente que si necesitas obtener inferencia de alta velocidad de modelos como Qwen 2 o Llama 3 en configuraciones de una sola GPU, entonces el líder indiscutible será la RTX™ 3090. Una posible alternativa podría ser la A40 o la L20. Pero no merece la pena ejecutar la inferencia de estos modelos en tarjetas Ampere de la generación A6000.

Deliberadamente no mencionamos en las pruebas las tarjetas con una cantidad menor de memoria de vídeo, por ejemplo, NVIDIA® RTX™ 2080Ti, ya que no es posible encajar allí los modelos 7B u 8B antes mencionados sin cuantización. Pues bien, el modelo Qwen 2 de 1,5B, por desgracia, no tiene respuestas de alta calidad y no puede servir como sustituto completo del 7B.
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




