





Tu propio Qwen usando HF

Los modelos de grandes redes neuronales, con sus extraordinarias capacidades, están firmemente arraigados en nuestras vidas. Reconociendo esto como una oportunidad de desarrollo futuro, las grandes corporaciones empezaron a desarrollar sus propias versiones de estos modelos. El gigante chino Alibaba no se quedó de brazos cruzados. Crearon su propio modelo, QWen (Tongyi Qianwen), que se convirtió en la base de muchos otros modelos de redes neuronales.
Requisitos previos
Actualizar caché y paquetes
Actualicemos la caché de paquetes y actualicemos nuestro sistema operativo antes de empezar a configurar Qwen. Además, necesitamos añadir Python Installer Packages (PIP), si no está ya presente en el sistema. Ten en cuenta que para esta guía, estamos utilizando Ubuntu 22.04 LTS como sistema operativo:
sudo apt update && sudo apt -y upgrade && sudo apt install python3-pipInstalar controladores NVIDIA®
Puede utilizar la utilidad automatizada que se incluye por defecto en las distribuciones de Ubuntu:
sudo ubuntu-drivers autoinstallAlternativamente, puedes instalar los controladores NVIDIA® manualmente usando nuestra guía paso a paso. No olvides reiniciar el servidor:
sudo shutdown -r nowInterfaz web de generación de texto
Clonar el repositorio
Abra el directorio de trabajo en el SSD:
cd /mnt/fastdiskClona el repositorio del proyecto:
git clone https://github.com/oobabooga/text-generation-webui.gitInstalar requisitos
Abra el directorio descargado:
cd text-generation-webuiCompruebe e instale todos los componentes que faltan:
pip install -r requirements.txtAñadir clave SSH a HF
Antes de empezar, necesita configurar el reenvío de puertos (puerto remoto 7860 a 127.0.0.1:7860) en su cliente SSH. Puede encontrar información adicional en el siguiente artículo: Conectarse al servidor Linux.
Actualice el repositorio caché de paquetes y los paquetes instalados:
sudo apt update && sudo apt -y upgradeGenera y añade una clave SSH que puedas utilizar en Hugging Face:
cd ~/.ssh && ssh-keygenCuando se genera el par de claves, puede mostrar la clave pública en el emulador de terminal:
cat id_rsa.pubCopie toda la información empezando por ssh-rsa y terminando por usergpu@gpuserver como se muestra en la siguiente captura de pantalla:
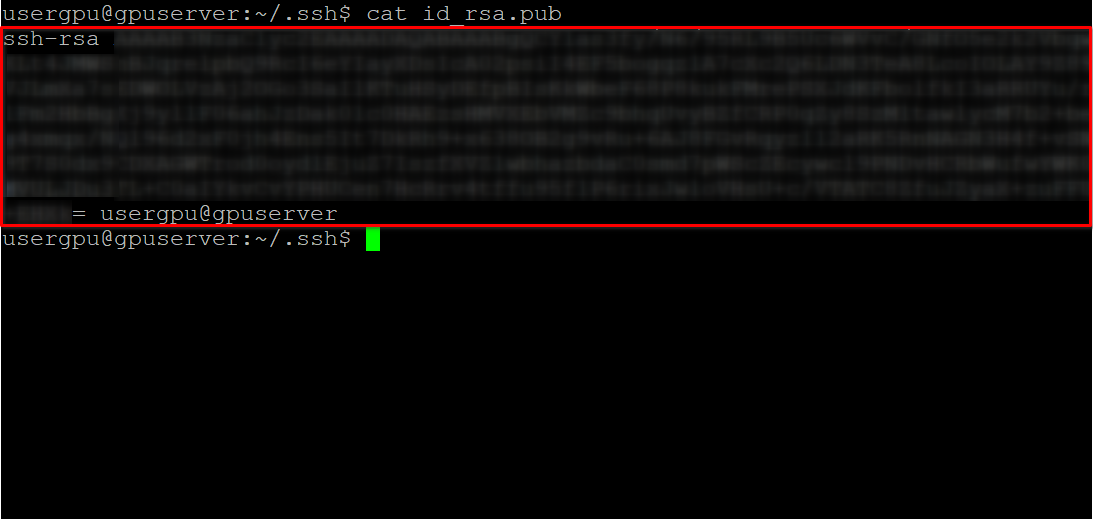
Abre un navegador web, escribe https://huggingface.co/ en la barra de direcciones y pulsa Enter. Accede a tu cuenta HF y abre Profile settings. A continuación, seleccione SSH and GPG Keys y pulse el botón Add SSH Key:
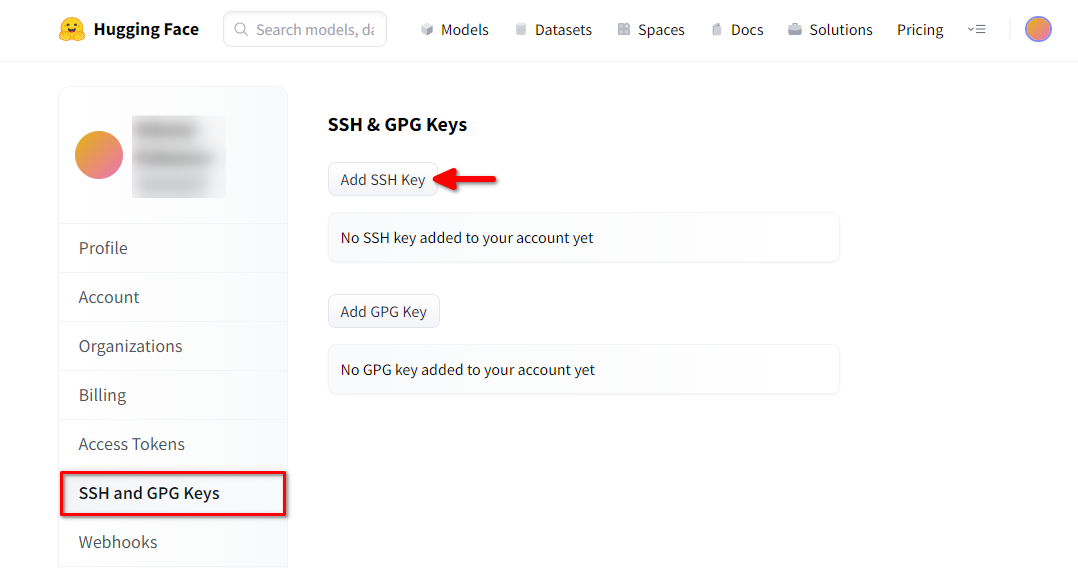
Rellena el Key name y pega el SSH Public key copiado del terminal. Guarda la clave pulsando Add key:
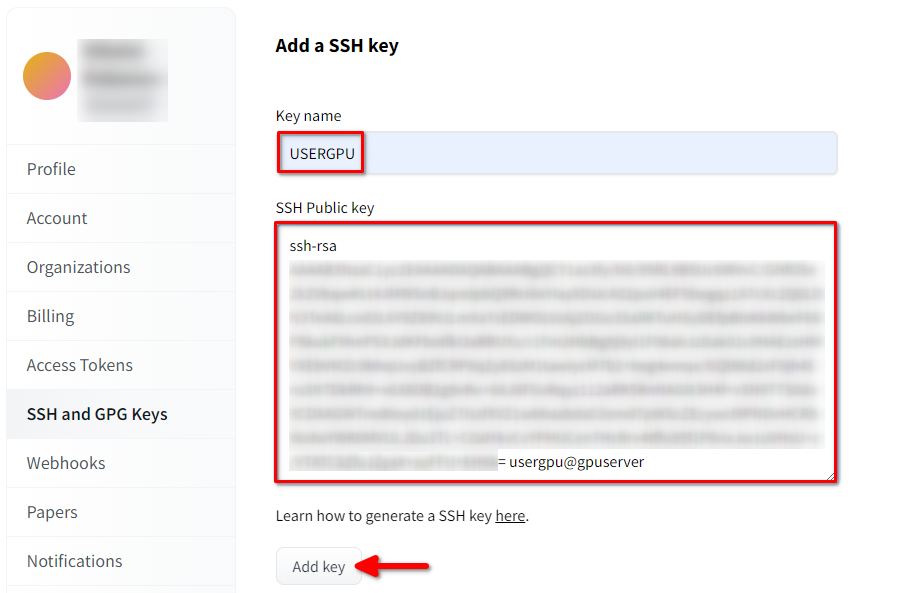
Ahora, tu cuenta HF está vinculada a la clave SSH pública. La segunda parte (clave privada) se almacena en el servidor. El siguiente paso es instalar una extensión específica de Git LFS (Large File Storage), que se utiliza para descargar archivos de gran tamaño, como los modelos de redes neuronales. Abre tu directorio de inicio:
cd ~/Descargue y ejecute el script de shell. Este script instala un nuevo repositorio de terceros con git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashAhora, puedes instalarlo usando el gestor de paquetes estándar:
sudo apt-get install git-lfsVamos a configurar git para utilizar nuestro apodo HF:
git config --global user.name "John"Y vinculado a la cuenta de correo de HF:
git config --global user.email "john.doe@example.com"Descargar el modelo
El siguiente paso consiste en descargar el modelo mediante la técnica de clonación de repositorios utilizada habitualmente por los desarrolladores de software. La única diferencia es que el Git-LFS previamente instalado procesará automáticamente los ficheros punteros marcados y descargará todo el contenido. Abre el directorio necesario (/mnt/fastdisk en nuestro ejemplo):
cd /mnt/fastdiskEste comando puede tardar algún tiempo en completarse:
git clone git@hf.co:Qwen/Qwen1.5-32B-Chat-GGUFEjecutar el modelo
Ejecute un script que iniciará el servidor web y especificará /mnt/fastdisk como directorio de trabajo con los modelos. Este script puede descargar algunos componentes adicionales en el primer lanzamiento.
./start_linux.sh --model-dir /mnt/fastdiskAbra su navegador web y seleccione llama.cpp en la lista desplegable Model loader:
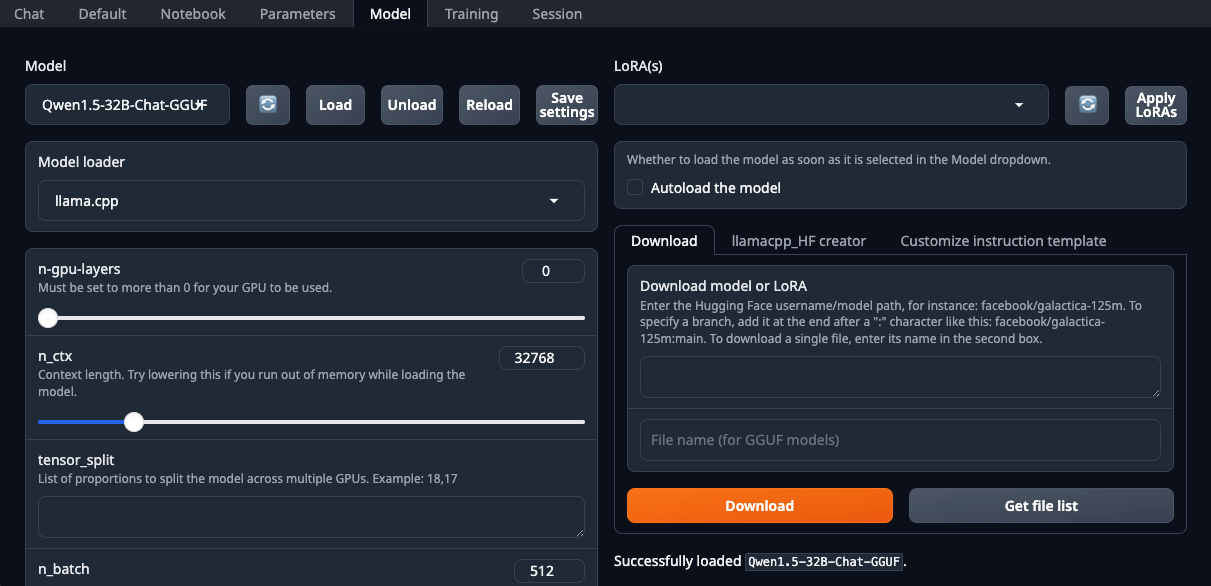
Asegúrese de configurar el parámetro n-gpu-layers. Es el responsable de qué porcentaje de cálculos se descargarán a la GPU. Si dejas el número en 0, todos los cálculos se realizarán en la CPU, lo cual es bastante lento. Una vez configurados todos los parámetros, haz clic en el botón Load. Después, vaya a la pestaña Chat y seleccione Instruct mode. Ahora, puede introducir cualquier pregunta y recibir una respuesta:
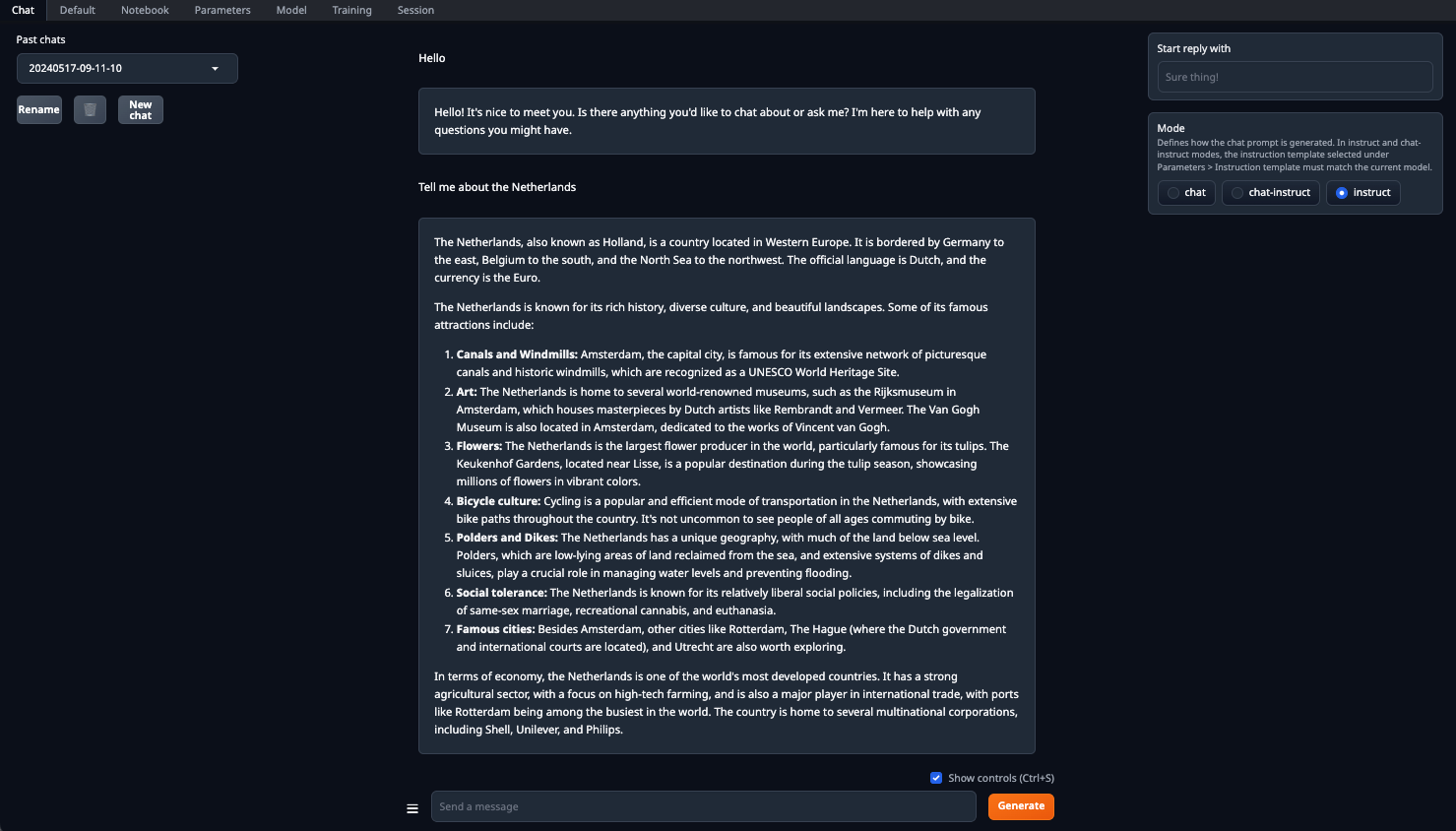
El procesamiento se realizará por defecto en todas las GPUs disponibles, teniendo en cuenta los parámetros especificados previamente:
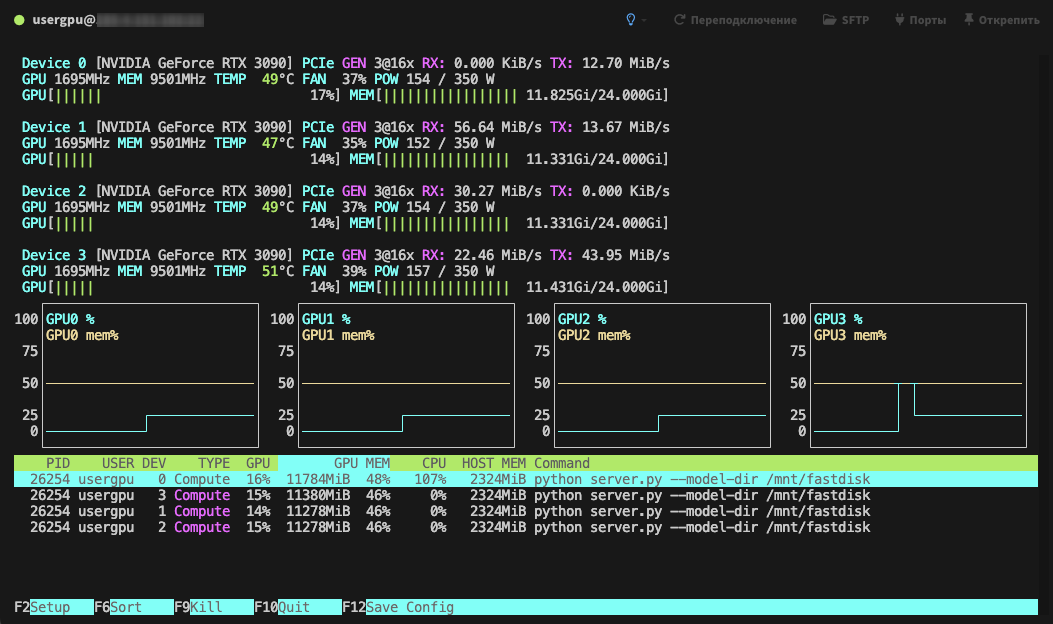
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




