





Tu propia Vicuña en Linux

Este artículo te guiará a través del proceso de despliegue de una alternativa LLaMA básica en un servidor LeaderGPU. Para ello utilizaremos el proyecto FastChat y el modelo Vicuna de libre acceso.
El modelo que utilizaremos está basado en la arquitectura LLaMA de Meta pero ha sido optimizado para un despliegue eficiente en hardware de consumo. Esta configuración proporciona un buen equilibrio entre el rendimiento y los requisitos de recursos, por lo que es adecuado tanto para pruebas como para entornos de producción.
Preinstalación
Preparémonos para instalar FastChat actualizando el repositorio caché de paquetes:
sudo apt update && sudo apt -y upgradeInstala los drivers de NVIDIA® automáticamente usando el siguiente comando:
sudo ubuntu-drivers autoinstallTambién puede instalar estos controladores manualmente con nuestra guía paso a paso. A continuación, reinicie el servidor:
sudo shutdown -r nowEl siguiente paso es instalar PIP (Package Installer for Python):
sudo apt install python3-pipInstalar FastChat
Desde PyPi
Hay dos formas posibles de instalar FastChat. Puedes instalarlo directamente desde PyPi:
pip3 install "fschat[model_worker,webui]"Desde GitHub
Alternativamente, puedes clonar el repositorio de FastChat desde GitHub e instalarlo:
git clone https://github.com/lm-sys/FastChat.gitcd FastChatNo olvides actualizar PIP antes de continuar:
pip3 install --upgrade pippip3 install -e ".[model_worker,webui]"Ejecutar FastChat
Primer inicio
Para garantizar el éxito del primer inicio, se recomienda llamar manualmente a FastChat directamente desde la línea de comandos:
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5Esta acción recupera y descarga automáticamente el modelo designado de su elección, que debe especificarse mediante el parámetro --model-path. El 7b representa un modelo con 7.000 millones de parámetros. Se trata del modelo más ligero, adecuado para GPUs con 16 GB de memoria de vídeo. En el archivo Léame del proyecto encontrarás enlaces a modelos con un mayor número de parámetros.
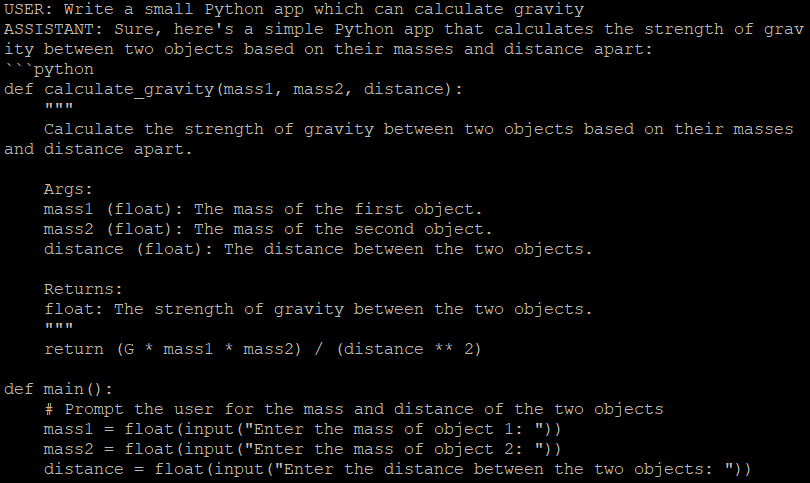
Ahora tienes la opción de entablar una conversación con el chatbot directamente dentro de la interfaz de línea de comandos o puedes configurar una interfaz web. Contiene tres componentes:
- Controlador
- Trabajadores
- Servidor web de Gradio
Configurar servicios
Transformemos cada componente en un servicio systemd independiente. Crea 3 archivos separados con el siguiente contenido:
sudo nano /etc/systemd/system/vicuna-controller.service[Unit]
Description=Vicuna controller service
[Service]
User=usergpu
WorkingDirectory=/home/usergpu
ExecStart=python3 -m fastchat.serve.controller
Restart=always
[Install]
WantedBy=multi-user.targetsudo nano /etc/systemd/system/vicuna-worker.service[Unit]
Description=Vicuna worker service
[Service]
User=usergpu
WorkingDirectory=/home/usergpu
ExecStart=python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
Restart=always
[Install]
WantedBy=multi-user.targetsudo nano /etc/systemd/system/vicuna-webserver.service[Unit]
Description=Vicuna web server
[Service]
User=usergpu
WorkingDirectory=/home/usergpu
ExecStart=python3 -m fastchat.serve.gradio_web_server
Restart=always
[Install]
WantedBy=multi-user.targetSystemd suele actualizar su base de datos de demonios durante el proceso de arranque del sistema. Sin embargo, puede hacerlo manualmente utilizando el siguiente comando:
sudo systemctl daemon-reloadAhora, agreguemos tres nuevos servicios al inicio y lancémoslos inmediatamente usando la opción --now:
sudo systemctl enable vicuna-controller.service --now && sudo systemctl enable vicuna-worker.service --now && sudo systemctl enable vicuna-webserver.service --nowSin embargo, si intenta abrir una interfaz web en http://[DIRECCIÓN_IP]:7860, se encontrará con una interfaz completamente inutilizable y sin modelos disponibles. Para resolver este problema, detenga el servicio de interfaz web:
sudo systemctl stop vicuna-webserver.serviceEjecute el servicio web manualmente:
python3 -m fastchat.serve.gradio_web_serverAñadir una autenticación
Esta acción llama a otro script, que registrará el modelo previamente descargado en una base de datos interna de Gradio. Espera unos segundos e interrumpe el proceso utilizando el acceso directo Ctrl + C. También nos ocuparemos de la seguridad y activaremos un sencillo mecanismo de autenticación para acceder a la interfaz web. Abre el siguiente archivo si instalaste FastChat desde PyPI:
sudo nano /home/usergpu/.local/lib/python3.10/site-packages/fastchat/serve/gradio_web_server.pyo
sudo nano /home/usergpu/FastChat/fastchat/serve/gradio_web_server.pyDesplácese hasta el final. Encuentra esta línea:
auth=auth,
Cámbiala poniendo el nombre de usuario o la contraseña que quieras:
auth=(“username”,”password”),Guarde el archivo y salga, usando el acceso directo Ctrl + X. Por último, inicie la interfaz web:
sudo systemctl start vicuna-webserver.serviceAbre http://[IP_ADDRESS]:7860 en tu navegador y disfruta de FastChat con Vicuña:
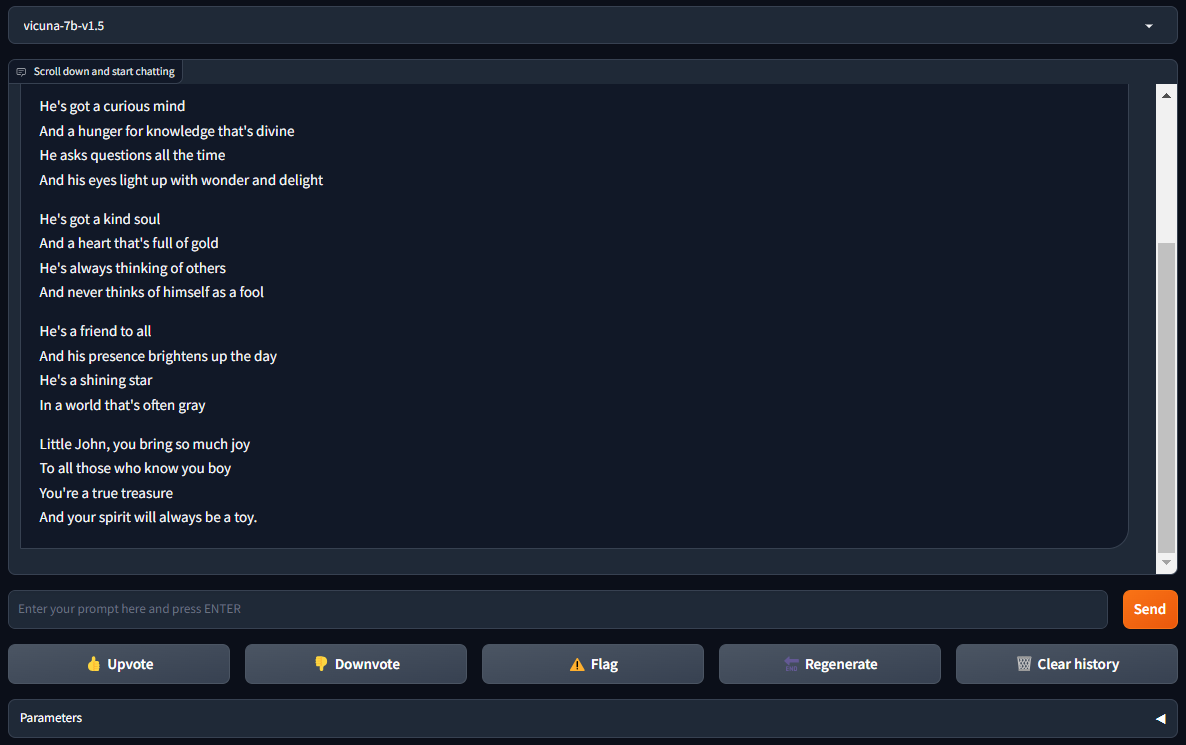
Ver también:
Actualizado: 04.01.2026
Publicado: 20.01.2025




