





Evaluación comparativa de Tensorflow ResNet-50
Evaluación comparativa de Tensorflow™ ResNet-50
LeaderGPU® es un servicio que ha entrado en el mercado del GPU computing con serias intenciones desde hace tiempo. La velocidad de los cálculos para el modelo ResNet-50 en LeaderGPU® es 2,5 veces más rápida en comparación con Google Cloud, y 2,9 veces más rápida en comparación con AWS (los datos se proporcionan para un ejemplo con 8x GTX 1080 en comparación con 8x Tesla® K80). El coste de alquiler por minuto de la GPU en LeaderGPU® comienza a partir de tan solo 0,02 euros, lo que es más de 4 veces inferior al coste de alquiler en Google Cloud y más de 5 veces inferior al coste en AWS (a 7 de julio de 207).
A lo largo de este artículo, probaremos el modelo ResNet-50 en servicios tan populares como LeaderGPU®, AWS y Google Cloud. Podrás ver en la práctica por qué LeaderGPU® supera significativamente a los competidores representados.
Todas las pruebas se realizaron utilizando python 3.5 y Tensorflow-gpu 1.2 en máquinas con GTX 1080, GTX 1080 TI y Tesla® P 100 con el sistema operativo CentOS 7 instalado y la librería CUDA® 8.0.
Se utilizaron los siguientes comandos para ejecutar la prueba:
git clone https://github.com/tensorflow/benchmarks.gitpython3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Number of cards on the server) --model resnet50 --batch_size 32 (64, 128, 256, 512)Instancias GTX 1080
Para la primera prueba, utilizamos instancias con la GTX 1080. A continuación se ofrecen los datos del entorno de prueba (con tamaños de lote de 32 y 64):
- Tipos de instancia: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- Sistema operativo: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Comando: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (opcional 64, 128,256, 512)
- Modelo ResNet50
- Fecha de la prueba: junio de 2017
Los resultados de la prueba se muestran en el siguiente diagrama:

Instancias GTX 1080TI
El siguiente paso consiste en probar instancias con la GTX 1080 Ti. A continuación se ofrecen los datos del entorno de prueba (con tamaños de lote de 32, 64 y 128):
- Tipos de instancia: ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- SO: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Comando: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (opcional 64, 128,256, 512)
- Modelo ResNet50
- Fecha de la prueba: junio de 2017
Los resultados de la prueba se muestran en el siguiente diagrama:

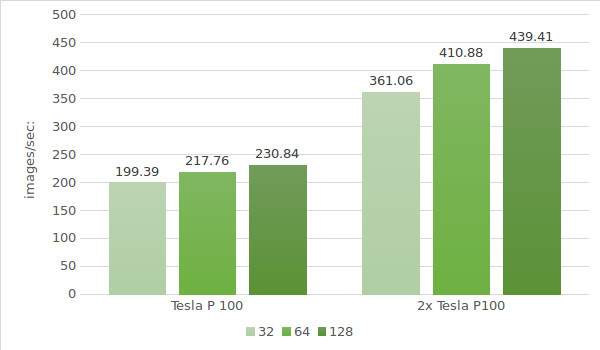
Instancia Tesla® P100
El paso final es probar instancias con Tesla® P100. A continuación se proporcionan los datos del entorno de prueba (con tamaños de lote 32, 64 y 128):
- Tipo de instancia: 2x NVIDIA® Tesla® P100
- SO: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Comando: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (opcional 64, 128, 256, 512)
- Modelo ResNet50
- Fecha de la prueba: junio de 2017
Los resultados de la prueba se muestran en el siguiente diagrama:
La siguiente tabla representa los resultados de la prueba Resnet50 para la nube de Google y AWS (tamaño de lote 64):
| GPU | Nube de Google | AWS |
|---|---|---|
| 1x Tesla® K80 | 51.9 | 51.5 |
| 2x Tesla® K80 | 99 | 98 |
| 4x Tesla® K80 | 195 | 195 |
| 8x Tesla® K80 | 387 | 384 |
* Los datos facilitados proceden de las siguientes fuentes:
https://www.tensorflow.org/performance/benchmarks#details_for_google_compute_engine_nvidia_tesla_k80 https://www.tensorflow.org/performance/benchmarks#details_for_amazon_ec2_nvidia_tesla_k80
Calculemos el coste y el tiempo de procesamiento para 1.000.000 de imágenes en cada máquina LeaderGPU®, AWS y Google. El recuento está disponible con un tamaño de lote de 64 para todas las máquinas.
| GPU | Número de imágenes | Tiempo | Precio (por minuto) | Coste total |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15seg | 0,02 € | 1,29 € |
| 4x GTX 1080 | 1000000 | 34m 17seg | 0,03 € | 1,03 € |
| 8x GTX 1080 | 1000000 | 17m 32seg | 0,09 € | 1,58 € |
| 4x GTX 1080TI | 1000000 | 23m 34seg | 0,04 € | 0,94 € |
| 2х Tesla® P100 | 1000000 | 40m 33seg | 0,08 € | 3,24 € |
| 8x Tesla® K80 Nube de Google | 1000000 | 43m 3seg | 0,0825 €** | 3,55 € |
| 8x Tesla® K80 AWS | 1000000 | 43m 24seg | 0,107 € | 4,64 € |
** El servicio en la nube de Google no ofrece planes de pago por minuto. Los cálculos del coste por minuto se basan en el precio por hora (5,645 $).
Como puede deducirse de la tabla, la velocidad de procesamiento de imágenes en el modelo ResNet-50 es máxima con 8x GTX 1080 de LeaderGPU®, mientras que:
- El coste de arrendamiento inicial en LeaderGPU® parte de tan solo 1,28 euros, lo que supone unas 2,77 veces menos que en las instancias de 8x Tesla® K80 de Google Cloud, y unas 4,38 veces menos que en las instancias de 8x Tesla® K80 de Google AWS;
- el tiempo de procesamiento fue de 17 minutos y 32 segundos, lo que es 2,5 veces más rápido que en las instancias de 8x Tesla® K80 de Google Cloud, y 2,49 veces más rápido que en las instancias de 8x Tesla® K80 de Google AWS.
LeaderGPU® supera significativamente a sus competidores tanto en disponibilidad del servicio como en velocidad de procesamiento de imágenes. ¡Alquile una GPU con un pago por minuto en LeaderGPU® para resolver diversas tareas en el menor tiempo posible!
LEGAL WARNING:
PLEASE READ THE LICENSE FOR CUSTOMER USE OF NVIDIA® GEFORCE® SOFTWARE CAREFULLY BEFORE AGREEING TO IT, AND MAKE SURE YOU USE THE SOFTWARE IN ACCORDANCE WITH THE LICENSE, THE MOST IMPORTANT PROVISION IN THIS RESPECT BEING THE FOLLOWING LIMITATION OF USE OF THE SOFTWARE IN DATACENTERS:
«No Datacenter Deployment. The SOFTWARE is not licensed for datacenter deployment, except that blockchain processing in a datacenter is permitted.»
Customer may use the LeaderGPU® Services for blockchain processing.
BY AGREEING TO THE LICENSE AND DOWNLOADING THE SOFTWARE YOU GUARANTEE THAT YOU WILL MAKE CORRECT USE OF THE SOFTWARE AND YOU AGREE TO INDEMNIFY AND HOLD US HARMLESS FROM ANY CLAIMS, DAMAGES OR LOSSES RESULTING FROM ANY INCORRECT USE OF THE SOFTWARE BY YOU.
Actualizado: 04.01.2026
Publicado: 07.12.2017